
구글로 검색한 결과 이미지를 크롤링하는 방법을 포스팅해 보겠습니다.
현재 데이터 수집과 관련하여 구글 이미지 크롤링을 시도해볼까 생각이 들어 코드를 수정해 보았습니다.
Selenium으로 구글 이미지 크롤링
1. 파이썬 가상 환경 구성
우선 파이썬 가상환경 구성부터 해볼 겁니다.
가상환경 구성을 습관화하는 게 좋은 이유는 ('저도 알고 싶지 않았습니다'가 아니라) 서로 다른 프로젝트가 서로 다른 라이브러리 버전을 필요로 할 때, 가상환경을 사용하면 프로젝트별로 독립적인 환경을 구성하여 버전 충돌을 방지할 수 있기 때문입니다.
conda를 사용해서 하는 방법도 있고 venv를 사용해서 구성하는 방법도 있는데 이번에는 venv를 사용해서 구성해 보았습니다. (conda를 사용해서 하는 방법은 이 링크를 참조해 주시길 바랍니다.)
저는 vscode를 주로 사용하기 때문에 vscode의 terminal 창을 열어서 아래와 같은 명령어를 입력해 줍니다.
env_name에 생성할 가상환경 이름을 적어 넣으시면 됩니다.
# 가상환경 생성
python -m venv env_name
# 가상환경 적용 (Windows)
env_name\Scripts\activate
# 가상환경 적용 (Linux/Mac)
source env_name/bin/activate
그러면 가상환경이 활성화되었을 것입니다. 저희는 파이썬의 Selenium이라는 라이브러리를 사용할 것이기 때문에 아래 명령어로 selenium을 다운로드하여줍니다.
pip install selenium2. Chromedriver 다운로드
크롤링을 위해서는 chromedriver가 필요합니다. 해당 드라이버를 설치하기 전에 우선 본인이 사용하고 있는 chrome 버전확인 과정이 필요합니다.
크롬으로 접속해서 우측 상단의 점 세 개를 클릭하고 목록 하단 부의 설정에 들어가 줍니다.
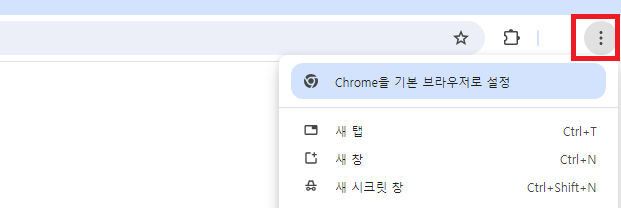
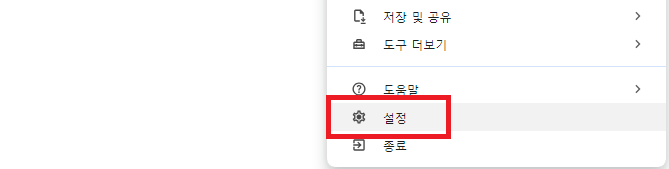
설정에 들어가면 좌측 하단 Chrome 정보에서 본인이 사용하고 있는 Chrome의 버전을 확인할 수 있습니다.
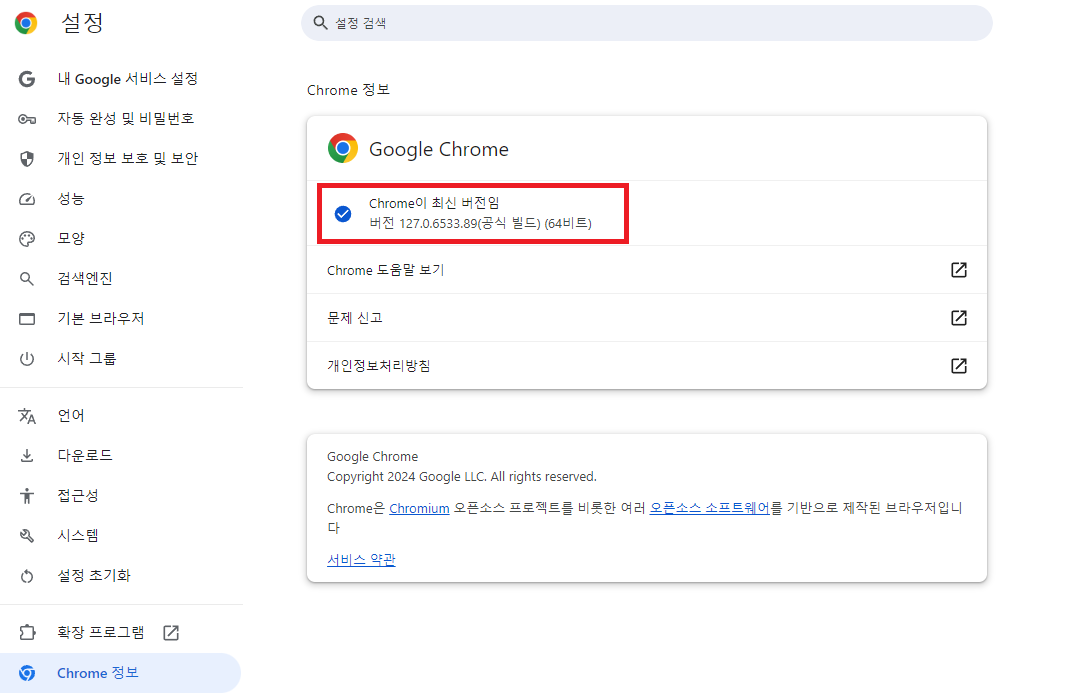
버전에 맞는 Chromedriver를 다운로드하기 위해서 114 이전 버전은 아래 링크에 접속하시면 되고
https://sites.google.com/chromium.org/driver/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 115 or newer, please consult the Chrome for Testing availability dashboard. This page provides convenient JSON endpoints for specific ChromeDriver version downloading. For older versions of Chrome, please se
sites.google.com
저의 경우에는 115보다 최신 버전이었기 때문에 아래 페이지에 접속해서 다운을 받았습니다.
https://googlechromelabs.github.io/chrome-for-testing/
Chrome for Testing availability
chrome-headless-shellmac-arm64https://storage.googleapis.com/chrome-for-testing-public/127.0.6533.88/mac-arm64/chrome-headless-shell-mac-arm64.zip200
googlechromelabs.github.io
일치하는 버전이 없어도 비슷한 버전으로 다운로드하시면 됩니다.
zip 파일을 다운로드하게 되실 텐데요, zip 파일 안의 chromedriver.exe를 본인이 크롤링 코드를 돌릴 디렉터리 안에 복사해서 사용하시면 됩니다.
3. 크롤링 코드 (1)
(1이 있음은 추가 수정된 코드 2가 있기 때문입니다. 설명을 건너 뛰셔도 이해가 가능한 분들은 아래 링크로 접속하셔서 코드를 확인하시기 바랍니다.)
ksy5098/selenium-google-images-crawler: selenium google images crawler (github.com)
GitHub - ksy5098/selenium-google-images-crawler: selenium google images crawler
selenium google images crawler. Contribute to ksy5098/selenium-google-images-crawler development by creating an account on GitHub.
github.com
여느 코드도 마찬가지지만 크롤링을 하기 위해서 코드를 찾아서 막상 적용해 보면 기존 크롤링 코드를 그대로 사용했을 때 오류가 나는 경우가 많습니다.
다음과 같은 이유가 있습니다.
- selenium 문법의 변화 때문입니다. 이전에 사용했던 문법이 없어지고 새로운 문법으로 바뀌면서 기존 코드를 수정해야 하는 경우가 생깁니다.
예를 들어, 이전에 find_element_by _class 와 같은 형식의 문법이 find_element(By.CLASS_NAME, "gLFyf")로 바뀐 것을 확인할 수 있었습니다. - 내가 크롤링하고자 하는 부분을 class name 등의 attribute을 이용해서 접근하게 되는데 그 부분이 시간이 지나면서 바뀌기 때문입니다.
현재 시점에서 오류가 나지 않는 크롤링 코드에 대해서 설명드리겠습니다. 이 코드도 언젠가 오류가 날 때 위 부분을 확인해 보시면 금방 오류를 수정해서 사용하실 수 있을 겁니다!
이제 본격적으로 코드의 핵심 부분을 순서대로 설명드리겠습니다.
다음은 라이브러리를 불러오는 부분입니다. 기본적으로 크롤링을 할 때 필요한 selenium과 필요한 것들을 불러옵니다.
- selenium 관련 모듈: 웹 브라우저를 자동화하는 데 사용됨
- urllib.request: URL에서 데이터를 가져오는 데 사용됨
- os: 파일 시스템 작업을 위해 사용됨
- time: 작업 중간에 시간 지연을 위해 사용됨
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import urllib.request
import os
import time
다음은 Selenium 웹드라이버 설정하는 부분입니다. 이 코드까지 실행시키면 Chrome 웹드라이버를 설정하고 Google 이미지 검색 페이지를 여는 것을 확인할 수 있습니다.
service = Service(executable_path="chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
다음은 검색어를 입력하고 검색을 실행하는 부분입니다.
아래 부분에서 CLASS_NAME과 gLFyf가 있는데 이 부분은 다음 설명을 보시면 이해가 되실 겁니다.
input_element = driver.find_element(By.CLASS_NAME, "gLFyf")
input_element.send_keys(search_query + Keys.ENTER)
구글 검색창 첫 화면에서 F12를 눌러서 개발자도구를 열면 다음과 같은 화면이 나옵니다. 오른쪽에는 html이 나와있는 것을 확인하실 수 있습니다.
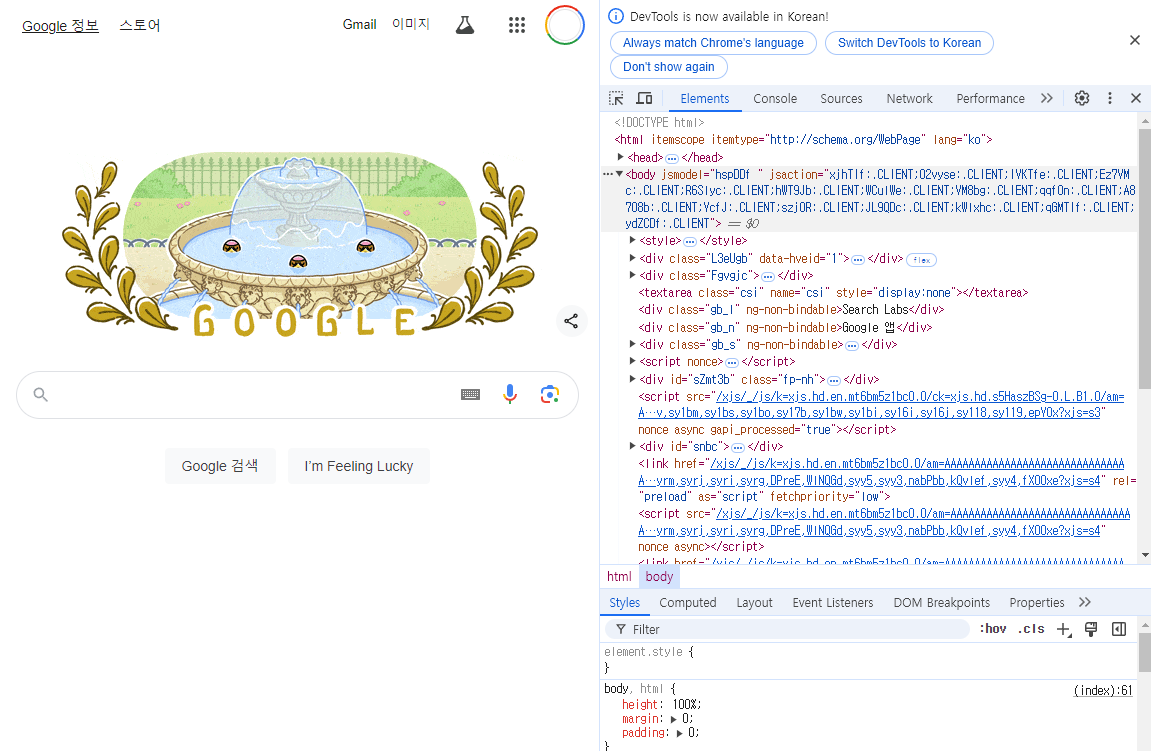
아래 노란색 형광펜이 쳐져있는 곳을 보면 검색하는 공간 class 이름이 " gLFyf"인 것을 확인할 수 있습니다.
이렇게 html를 뜯어보면서 원하는 부분에 접근하여 src를 가져오거나 이미지를 다운로드하는 등의 명령을 내리는 방식으로 코드를 구성하시면 됩니다.
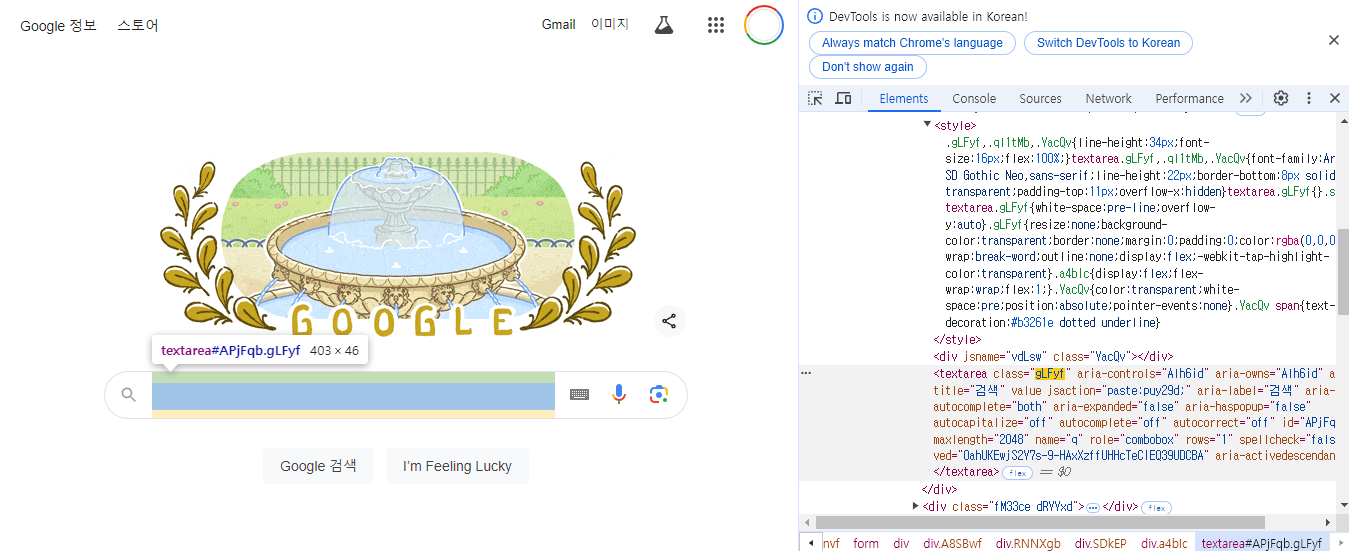
위 코드를 다시 설명하면 class이름이 gLFyf인 element를 찾아서 검색할 단어를 입력받아 검색하는 코드입니다.
이미지를 다운로드하기 위해서 웹페이지 검색 화면을 끝까지 스크롤해주는 작업이 필요합니다.
아래 코드가 이를 실행해 줍니다.
elem = driver.find_element(By.TAG_NAME, 'body')
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
try:
view_more_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'mye4qd')))
view_more_button.click()
for i in range(80):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
다음은 이미지 링크를 수집하는 코드입니다.
아래 화면을 보면 img 뒤에 YQ4 gaf가 붙어있는데 html 코드를 직즙 확인해보시면 모든 이미지의 class 이름이 YQ4gaf 인 것을 확인하실 수 있습니다. (닝닝.. 🤍)
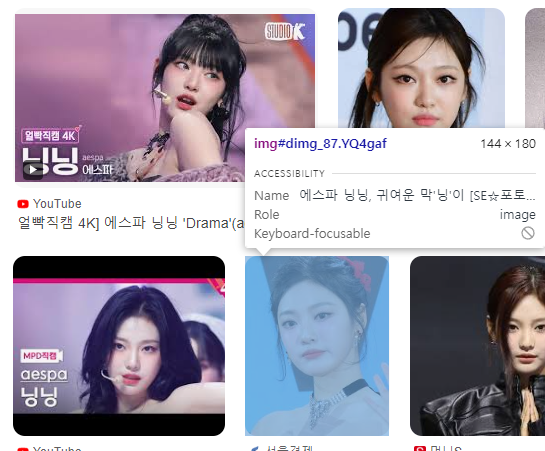
따라서 코드는 아래와 같이 작성해 줍니다.
images = driver.find_elements(By.CLASS_NAME, "YQ4gaf")
links = []
for image in images:
class_attribute = image.get_attribute('class')
title_attribute = image.get_attribute('title')
# 이미지 클래스가 특정 클래스 조합이 아닐 때만 다운로드 리스트에 추가
if "YQ4gaf zr758c" not in class_attribute and "YQ4gaf zr758c wA1Bge" not in class_attribute :
if title_attribute != "파리 2024 아티스틱 스위밍":
src = image.get_attribute('src')
if src:
links.append(src)
중간에 "if "YQ4gaf zr758c" not in class_attribute and "YQ4gaf zr758c wA1Bge" not in class_attribute :
if title_attribute != "파리 2024 아티스틱 스위밍":"
부분은 크롤링할 때 위에 뜨는 조그만 사진과

사진 아래의 각종 로고,

그리고 검색창 옆에 뜨는 아래 이미지도 같이 크롤링되는 것을 방지하기 위해서 넣어둔 코드입니다!

(수정 전에 이렇게 크롤링되었었음)
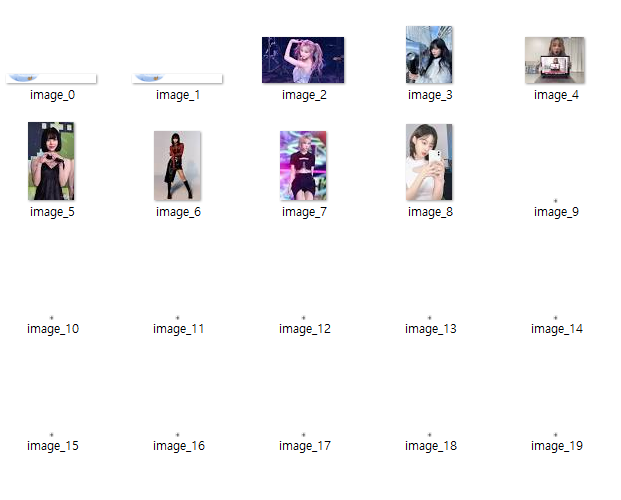
전체 코드 (version 1)
따라서 전체 코드는 아래에 있는 코드가 되는데 사실 이것은 최종 코드가 아닙니다.
아래 코드를 실행해 보면 잘 실행되긴 하는데 화면에 잘 담기는지 모르겠지만, 사진 크기가 가로 세로 180~200 밖에 되지 않습니다. 이유는 검색했을 때 나오는 화면의 사진을 그대로 가져오기 때문입니다.
이에 또 코드를 2차로 수정하였습니다!
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import urllib.request
import os
import time
# Selenium 웹드라이버 설정
service = Service(executable_path="chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
# 검색어 및 다운로드할 이미지 수 입력 받기
search_query = input("검색할 단어: ")
num_images_to_download = int(input("다운로드할 이미지 개수: "))
# 검색어 입력 및 검색 실행
input_element = driver.find_element(By.CLASS_NAME, "gLFyf")
input_element.send_keys(search_query + Keys.ENTER)
# 스크롤 다운
elem = driver.find_element(By.TAG_NAME, 'body')
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
# '더보기' 버튼 클릭 (있을 경우)
try:
view_more_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'mye4qd')))
view_more_button.click()
for i in range(80):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
# 이미지 링크 수집
images = driver.find_elements(By.CLASS_NAME, "YQ4gaf")
links = []
for image in images:
class_attribute = image.get_attribute('class')
title_attribute = image.get_attribute('title')
# 이미지 클래스가 특정 클래스 조합이 아닐 때만 다운로드 리스트에 추가
if "YQ4gaf zr758c" not in class_attribute and "YQ4gaf zr758c wA1Bge" not in class_attribute :
if title_attribute != "파리 2024 아티스틱 스위밍":
src = image.get_attribute('src')
if src:
links.append(src)
print('다운로드 가능한 이미지의 총 개수:', len(links))
# 검색어를 기반으로 폴더 생성
download_path = os.path.join(os.getcwd(), search_query) # 현재 작업 디렉토리에 검색어 폴더 생성
os.makedirs(download_path, exist_ok=True)
# 이미지 다운로드
downloaded_count = 0
for k, url in enumerate(links):
if downloaded_count >= num_images_to_download:
break
if url:
filepath = os.path.join(download_path, f'{search_query} image_{k}.jpg')
try:
urllib.request.urlretrieve(url, filepath)
downloaded_count += 1
except Exception as e:
print(f'이미지 {k + 1} 다운로드 실패: {e}')
print(f'{downloaded_count}개의 이미지를 성공적으로 다운로드하였습니다.')
# 드라이버 종료
driver.quit()
4. 크롤링 코드 수정 (2) - 고화질 사진 다운로드
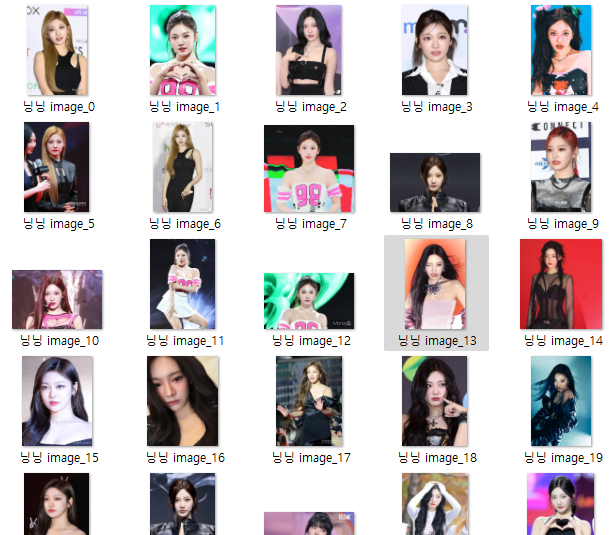
이번에는 검색을 실행하고 이미지를 하나씩 클릭해서 그때 나오는 고화질의 사진을 다운로드하는 방식으로 코드를 수정하였습니다. 결과는 다음과 같습니다.
(카리나 얼굴을 좀 더 고화질로 볼 수 있게 됨...!! )
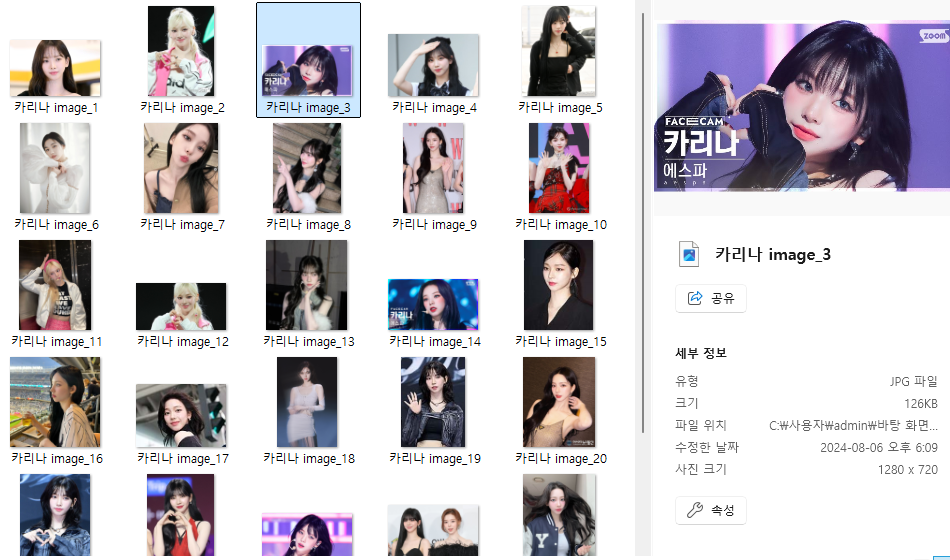
위 코드와 거의 비슷하므로 설명은 생략하겠습니다.
전체 코드 (version 2)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import urllib.request
import os
import time
# Selenium 웹드라이버 설정
service = Service(executable_path="chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
# 검색어 및 다운로드할 이미지 수 입력 받기
search_query = input("검색할 단어: ")
num_images_to_download = int(input("다운로드할 이미지 개수: "))
# 검색어 입력 및 검색 실행
input_element = driver.find_element(By.CLASS_NAME, "gLFyf")
input_element.send_keys(search_query + Keys.ENTER)
# 스크롤 다운
elem = driver.find_element(By.TAG_NAME, 'body')
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
# '더보기' 버튼 클릭 (있을 경우)
try:
view_more_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'mye4qd')))
view_more_button.click()
for i in range(80):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
# 검색어를 기반으로 폴더 생성
download_path = os.path.join(os.getcwd(), search_query) # 현재 작업 디렉토리에 검색어 폴더 생성
os.makedirs(download_path, exist_ok=True)
# 이미지 링크 수집
thumbnails = driver.find_elements(By.CLASS_NAME, "F0uyec")
print(thumbnails)
print('다운로드 가능한 이미지의 총 개수:', len(thumbnails))
# 이미지 다운로드
downloaded_count = 0
for index, thumbnail in enumerate(thumbnails):
if downloaded_count >= num_images_to_download:
break
try:
# 썸네일 클릭
driver.execute_script("arguments[0].click();", thumbnail)
# 고화질 이미지가 로드될 때까지 대기
high_res_image = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "sFlh5c.pT0Scc.iPVvYb"))
)
# 고화질 이미지의 src 속성 가져오기
high_res_src = high_res_image.get_attribute('src')
# 이미지 다운로드
if high_res_src and "http" in high_res_src:
filepath = os.path.join(download_path, f'image_{downloaded_count + 1}.jpg')
urllib.request.urlretrieve(high_res_src, filepath)
downloaded_count += 1
print(f'이미지 {downloaded_count} 다운로드 성공')
# 이미지 실패 시 예외 처리
except Exception as e:
print(f'이미지 {index + 1} 다운로드 실패: {e}')
continue
print(f'{downloaded_count}개의 이미지를 성공적으로 다운로드하였습니다.')
# 드라이버 종료
driver.quit()
도움이 되셨다면 좋겠습니다 •͈ᴗ•͈
구글로 검색한 결과 이미지를 크롤링하는 방법을 포스팅해 보겠습니다.
현재 데이터 수집과 관련하여 구글 이미지 크롤링을 시도해볼까 생각이 들어 코드를 수정해 보았습니다.
Selenium으로 구글 이미지 크롤링
1. 파이썬 가상 환경 구성
우선 파이썬 가상환경 구성부터 해볼 겁니다.
가상환경 구성을 습관화하는 게 좋은 이유는 ('저도 알고 싶지 않았습니다'가 아니라) 서로 다른 프로젝트가 서로 다른 라이브러리 버전을 필요로 할 때, 가상환경을 사용하면 프로젝트별로 독립적인 환경을 구성하여 버전 충돌을 방지할 수 있기 때문입니다.
conda를 사용해서 하는 방법도 있고 venv를 사용해서 구성하는 방법도 있는데 이번에는 venv를 사용해서 구성해 보았습니다. (conda를 사용해서 하는 방법은 이 링크를 참조해 주시길 바랍니다.)
저는 vscode를 주로 사용하기 때문에 vscode의 terminal 창을 열어서 아래와 같은 명령어를 입력해 줍니다.
env_name에 생성할 가상환경 이름을 적어 넣으시면 됩니다.
# 가상환경 생성
python -m venv env_name
# 가상환경 적용 (Windows)
env_name\Scripts\activate
# 가상환경 적용 (Linux/Mac)
source env_name/bin/activate
그러면 가상환경이 활성화되었을 것입니다. 저희는 파이썬의 Selenium이라는 라이브러리를 사용할 것이기 때문에 아래 명령어로 selenium을 다운로드하여줍니다.
pip install selenium2. Chromedriver 다운로드
크롤링을 위해서는 chromedriver가 필요합니다. 해당 드라이버를 설치하기 전에 우선 본인이 사용하고 있는 chrome 버전확인 과정이 필요합니다.
크롬으로 접속해서 우측 상단의 점 세 개를 클릭하고 목록 하단 부의 설정에 들어가 줍니다.
설정에 들어가면 좌측 하단 Chrome 정보에서 본인이 사용하고 있는 Chrome의 버전을 확인할 수 있습니다.
버전에 맞는 Chromedriver를 다운로드하기 위해서 114 이전 버전은 아래 링크에 접속하시면 되고
https://sites.google.com/chromium.org/driver/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 115 or newer, please consult the Chrome for Testing availability dashboard. This page provides convenient JSON endpoints for specific ChromeDriver version downloading. For older versions of Chrome, please se
sites.google.com
저의 경우에는 115보다 최신 버전이었기 때문에 아래 페이지에 접속해서 다운을 받았습니다.
https://googlechromelabs.github.io/chrome-for-testing/
Chrome for Testing availability
chrome-headless-shellmac-arm64https://storage.googleapis.com/chrome-for-testing-public/127.0.6533.88/mac-arm64/chrome-headless-shell-mac-arm64.zip200
googlechromelabs.github.io
일치하는 버전이 없어도 비슷한 버전으로 다운로드하시면 됩니다.
zip 파일을 다운로드하게 되실 텐데요, zip 파일 안의 chromedriver.exe를 본인이 크롤링 코드를 돌릴 디렉터리 안에 복사해서 사용하시면 됩니다.
3. 크롤링 코드 (1)
(1이 있음은 추가 수정된 코드 2가 있기 때문입니다. 설명을 건너 뛰셔도 이해가 가능한 분들은 아래 링크로 접속하셔서 코드를 확인하시기 바랍니다.)
ksy5098/selenium-google-images-crawler: selenium google images crawler (github.com)
GitHub - ksy5098/selenium-google-images-crawler: selenium google images crawler
selenium google images crawler. Contribute to ksy5098/selenium-google-images-crawler development by creating an account on GitHub.
github.com
여느 코드도 마찬가지지만 크롤링을 하기 위해서 코드를 찾아서 막상 적용해 보면 기존 크롤링 코드를 그대로 사용했을 때 오류가 나는 경우가 많습니다.
다음과 같은 이유가 있습니다.
- selenium 문법의 변화 때문입니다. 이전에 사용했던 문법이 없어지고 새로운 문법으로 바뀌면서 기존 코드를 수정해야 하는 경우가 생깁니다.
예를 들어, 이전에 find_element_by _class 와 같은 형식의 문법이 find_element(By.CLASS_NAME, "gLFyf")로 바뀐 것을 확인할 수 있었습니다. - 내가 크롤링하고자 하는 부분을 class name 등의 attribute을 이용해서 접근하게 되는데 그 부분이 시간이 지나면서 바뀌기 때문입니다.
현재 시점에서 오류가 나지 않는 크롤링 코드에 대해서 설명드리겠습니다. 이 코드도 언젠가 오류가 날 때 위 부분을 확인해 보시면 금방 오류를 수정해서 사용하실 수 있을 겁니다!
이제 본격적으로 코드의 핵심 부분을 순서대로 설명드리겠습니다.
다음은 라이브러리를 불러오는 부분입니다. 기본적으로 크롤링을 할 때 필요한 selenium과 필요한 것들을 불러옵니다.
- selenium 관련 모듈: 웹 브라우저를 자동화하는 데 사용됨
- urllib.request: URL에서 데이터를 가져오는 데 사용됨
- os: 파일 시스템 작업을 위해 사용됨
- time: 작업 중간에 시간 지연을 위해 사용됨
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import urllib.request
import os
import time
다음은 Selenium 웹드라이버 설정하는 부분입니다. 이 코드까지 실행시키면 Chrome 웹드라이버를 설정하고 Google 이미지 검색 페이지를 여는 것을 확인할 수 있습니다.
service = Service(executable_path="chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
다음은 검색어를 입력하고 검색을 실행하는 부분입니다.
아래 부분에서 CLASS_NAME과 gLFyf가 있는데 이 부분은 다음 설명을 보시면 이해가 되실 겁니다.
input_element = driver.find_element(By.CLASS_NAME, "gLFyf")
input_element.send_keys(search_query + Keys.ENTER)
구글 검색창 첫 화면에서 F12를 눌러서 개발자도구를 열면 다음과 같은 화면이 나옵니다. 오른쪽에는 html이 나와있는 것을 확인하실 수 있습니다.
아래 노란색 형광펜이 쳐져있는 곳을 보면 검색하는 공간 class 이름이 " gLFyf"인 것을 확인할 수 있습니다.
이렇게 html를 뜯어보면서 원하는 부분에 접근하여 src를 가져오거나 이미지를 다운로드하는 등의 명령을 내리는 방식으로 코드를 구성하시면 됩니다.
위 코드를 다시 설명하면 class이름이 gLFyf인 element를 찾아서 검색할 단어를 입력받아 검색하는 코드입니다.
이미지를 다운로드하기 위해서 웹페이지 검색 화면을 끝까지 스크롤해주는 작업이 필요합니다.
아래 코드가 이를 실행해 줍니다.
elem = driver.find_element(By.TAG_NAME, 'body')
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
try:
view_more_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'mye4qd')))
view_more_button.click()
for i in range(80):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
다음은 이미지 링크를 수집하는 코드입니다.
아래 화면을 보면 img 뒤에 YQ4 gaf가 붙어있는데 html 코드를 직즙 확인해보시면 모든 이미지의 class 이름이 YQ4gaf 인 것을 확인하실 수 있습니다. (닝닝.. 🤍)
따라서 코드는 아래와 같이 작성해 줍니다.
images = driver.find_elements(By.CLASS_NAME, "YQ4gaf")
links = []
for image in images:
class_attribute = image.get_attribute('class')
title_attribute = image.get_attribute('title')
# 이미지 클래스가 특정 클래스 조합이 아닐 때만 다운로드 리스트에 추가
if "YQ4gaf zr758c" not in class_attribute and "YQ4gaf zr758c wA1Bge" not in class_attribute :
if title_attribute != "파리 2024 아티스틱 스위밍":
src = image.get_attribute('src')
if src:
links.append(src)
중간에 "if "YQ4gaf zr758c" not in class_attribute and "YQ4gaf zr758c wA1Bge" not in class_attribute :
if title_attribute != "파리 2024 아티스틱 스위밍":"
부분은 크롤링할 때 위에 뜨는 조그만 사진과
사진 아래의 각종 로고,
그리고 검색창 옆에 뜨는 아래 이미지도 같이 크롤링되는 것을 방지하기 위해서 넣어둔 코드입니다!
(수정 전에 이렇게 크롤링되었었음)
전체 코드 (version 1)
따라서 전체 코드는 아래에 있는 코드가 되는데 사실 이것은 최종 코드가 아닙니다.
아래 코드를 실행해 보면 잘 실행되긴 하는데 화면에 잘 담기는지 모르겠지만, 사진 크기가 가로 세로 180~200 밖에 되지 않습니다. 이유는 검색했을 때 나오는 화면의 사진을 그대로 가져오기 때문입니다.
이에 또 코드를 2차로 수정하였습니다!
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import urllib.request
import os
import time
# Selenium 웹드라이버 설정
service = Service(executable_path="chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
# 검색어 및 다운로드할 이미지 수 입력 받기
search_query = input("검색할 단어: ")
num_images_to_download = int(input("다운로드할 이미지 개수: "))
# 검색어 입력 및 검색 실행
input_element = driver.find_element(By.CLASS_NAME, "gLFyf")
input_element.send_keys(search_query + Keys.ENTER)
# 스크롤 다운
elem = driver.find_element(By.TAG_NAME, 'body')
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
# '더보기' 버튼 클릭 (있을 경우)
try:
view_more_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'mye4qd')))
view_more_button.click()
for i in range(80):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
# 이미지 링크 수집
images = driver.find_elements(By.CLASS_NAME, "YQ4gaf")
links = []
for image in images:
class_attribute = image.get_attribute('class')
title_attribute = image.get_attribute('title')
# 이미지 클래스가 특정 클래스 조합이 아닐 때만 다운로드 리스트에 추가
if "YQ4gaf zr758c" not in class_attribute and "YQ4gaf zr758c wA1Bge" not in class_attribute :
if title_attribute != "파리 2024 아티스틱 스위밍":
src = image.get_attribute('src')
if src:
links.append(src)
print('다운로드 가능한 이미지의 총 개수:', len(links))
# 검색어를 기반으로 폴더 생성
download_path = os.path.join(os.getcwd(), search_query) # 현재 작업 디렉토리에 검색어 폴더 생성
os.makedirs(download_path, exist_ok=True)
# 이미지 다운로드
downloaded_count = 0
for k, url in enumerate(links):
if downloaded_count >= num_images_to_download:
break
if url:
filepath = os.path.join(download_path, f'{search_query} image_{k}.jpg')
try:
urllib.request.urlretrieve(url, filepath)
downloaded_count += 1
except Exception as e:
print(f'이미지 {k + 1} 다운로드 실패: {e}')
print(f'{downloaded_count}개의 이미지를 성공적으로 다운로드하였습니다.')
# 드라이버 종료
driver.quit()
4. 크롤링 코드 수정 (2) - 고화질 사진 다운로드
이번에는 검색을 실행하고 이미지를 하나씩 클릭해서 그때 나오는 고화질의 사진을 다운로드하는 방식으로 코드를 수정하였습니다. 결과는 다음과 같습니다.
(카리나 얼굴을 좀 더 고화질로 볼 수 있게 됨...!! )
위 코드와 거의 비슷하므로 설명은 생략하겠습니다.
전체 코드 (version 2)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import urllib.request
import os
import time
# Selenium 웹드라이버 설정
service = Service(executable_path="chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get("https://www.google.co.kr/imghp?hl=ko&ogbl")
# 검색어 및 다운로드할 이미지 수 입력 받기
search_query = input("검색할 단어: ")
num_images_to_download = int(input("다운로드할 이미지 개수: "))
# 검색어 입력 및 검색 실행
input_element = driver.find_element(By.CLASS_NAME, "gLFyf")
input_element.send_keys(search_query + Keys.ENTER)
# 스크롤 다운
elem = driver.find_element(By.TAG_NAME, 'body')
for i in range(60):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
# '더보기' 버튼 클릭 (있을 경우)
try:
view_more_button = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.CLASS_NAME, 'mye4qd')))
view_more_button.click()
for i in range(80):
elem.send_keys(Keys.PAGE_DOWN)
time.sleep(0.1)
except:
pass
# 검색어를 기반으로 폴더 생성
download_path = os.path.join(os.getcwd(), search_query) # 현재 작업 디렉토리에 검색어 폴더 생성
os.makedirs(download_path, exist_ok=True)
# 이미지 링크 수집
thumbnails = driver.find_elements(By.CLASS_NAME, "F0uyec")
print(thumbnails)
print('다운로드 가능한 이미지의 총 개수:', len(thumbnails))
# 이미지 다운로드
downloaded_count = 0
for index, thumbnail in enumerate(thumbnails):
if downloaded_count >= num_images_to_download:
break
try:
# 썸네일 클릭
driver.execute_script("arguments[0].click();", thumbnail)
# 고화질 이미지가 로드될 때까지 대기
high_res_image = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "sFlh5c.pT0Scc.iPVvYb"))
)
# 고화질 이미지의 src 속성 가져오기
high_res_src = high_res_image.get_attribute('src')
# 이미지 다운로드
if high_res_src and "http" in high_res_src:
filepath = os.path.join(download_path, f'image_{downloaded_count + 1}.jpg')
urllib.request.urlretrieve(high_res_src, filepath)
downloaded_count += 1
print(f'이미지 {downloaded_count} 다운로드 성공')
# 이미지 실패 시 예외 처리
except Exception as e:
print(f'이미지 {index + 1} 다운로드 실패: {e}')
continue
print(f'{downloaded_count}개의 이미지를 성공적으로 다운로드하였습니다.')
# 드라이버 종료
driver.quit()
도움이 되셨다면 좋겠습니다 •͈ᴗ•͈