
해당 포스팅은 <밑바닥부터 시작하는 딥러닝1> 책을 기준으로 하며, 공부 기록 목적으로 작성되었습니다.

기울기
모든 변수의 편미분을 벡터로 정리한 것을 기울기라고 한다. 기울기는 다음과 같이 구현할 수 있다.
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # x와 형상이 같고 모든 원소가 0인 배열을 생성
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h) 계산
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
return grad넘파이 배열의 x의 각 원소에 대해서 수치 미분을 구한다.
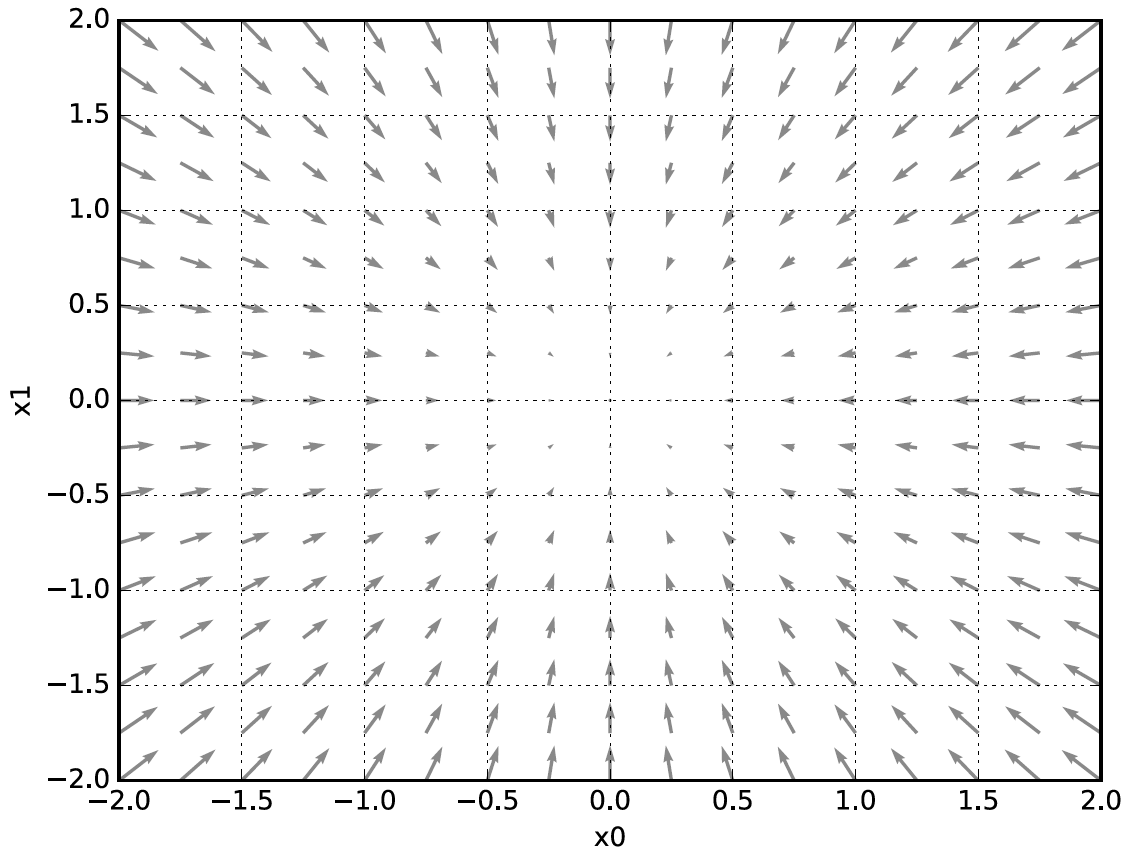
기울기 그림은 그림 4-9처럼 방향을 가진 벡터(화살표)로 그러진다. 기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향이다.
경사법(경사 하강법)
기계학습 문제 대부분은 학습 단계에서 최적의 매개변수를 찾아낸다. 신경망 역시 최적의 매개변수를 학습시에 찾아야 한다. 여기서 최적은 손실 함수가 최솟값이 될 때의 매개변수 값이다. 이런 상황에서 기울기를 잘 이용해 함수의 최솟값을 찾으려는 것이 경사법이다.
각 지점에서 함수의 값을 낮추는 방안을 제시하는 지표가 기울기인데 기울기가 가리키는 곳에 함수의 최솟값이 있는지, 그 쪽이 정말고 나아갈 방향인지는 보장할 수 없다. 실제로 복잡한 함수에서는 기울기가 가리키는 방향에 최솟값이 없는 경우가 대부분이다.
경사법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동하고 이동한 곳에서 기울기를 구하고 또 기울어진 방향으로 나아가기를 반복하는 방법이다. 경사법은 기계학습 최적화, 특히 신경망 학습에 많이 사용한다.
경사법은 최솟값을 찾는 경우 경사 하강법, 최댓값을 찾는 경우 경사 상승법이라고 한다. 경사법을 수식으로 나타내면 다음과 같다.
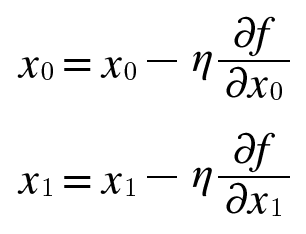
식 4.7에서 η(eta, 에타)는 갱신하는 양을 의미한다. 이를 신경망 학습에서는 학습률이라고 한다. 한 번의 학습으로 얼마만큼 학습해야 할지 매개변수 값을 얼마나 갱신하느냐를 정하는 것이 학습률이다.
학습률 값은 0.01이나 0.001 등 미리 특정 값으로 정해두어야 하는데 이 값이 너무 크거가 작으면 좋은 장소를 찾아갈 수 없다. 학습률이 너무 크면 큰 값으로 발산해버리고, 반대로 너무 작으면 거의 갱신되지 않은 채 학습이 끝나버린다. 따라서, 학습률 값을 변경하면서 올바르게 학습하고 있는지를 확인하면서 진행해야 한다.
경사 하강법은 다음과 같이 간단하게 구현할 수 있다.
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x인수 f는 최적화하려는 함수, init_x는 초깃값, lr은 learning rate, step_num은 경사법에 따른 반복 횟수를 뜻한다. 함수의 기울기는 numerical_gradient(f, x)로 구하고 그 기울기에 학습률을 곱한 값으로 갱신하는 처리를 step_num번 반복한다.
학습률 같은 매개변수를 하이퍼파라이머라고 한다. 가중치와 편향 같은 신경망의 매개변수와는 성질이 다른 매개변수로 사람이 직접 설정해야 한다. 여러 후보 값 중에서 시험을 통해 가장 잘 학습하는 값을 찾는 과정이 필요하다.
신경망에서의 기울기
신경망 학습에서는 가중치 매개변수에 대한 손실 함수의 기울기를 구해야 한다. 예를 들어, 형상이 2*3, 가중치가 W, 손실 함수가 L인 신경망이 있을 때, 경사는 식 4.8의 두 번째 식으로 나타낼 수 있다. 이의 각 원소는 각각의 원소에 관한 편미분이다.
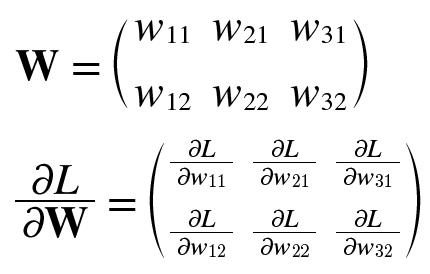
1행 1번째 원소는 w11을 조금 변경했을 때 손실 함수 L이 얼마나 변화하느냐를 의미한다. 여기서 중요한 점은 식 4.8의 두 행렬의 형상이 2*3로 같다는 것이다.
실제로 기울기를 구하는 코드는 다음과 같다.
import sys, os
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
# softmax, cross_entropy_error, numerical_gradient는 가져다 사용
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 정규분포로 초기화
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
# def f(W): return net.loss(x, t)
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)추가 작성 예정
학습 알고리즘 구현하기
2층 신경망 클래스 구현하기
미니배치 학습 구현하기
시험 데이터로 평가하기
정리
- 기계 학습에서 사용하는 데이터셋은 훈련 데이터와 시험 데이터로 나눠 사용한다.
- 훈련 데이터로 학습한 모델의 범용 능력을 시험 데이터로 평가한다.
- 신경망 학습은 손실 함수를 지표로, 손실 함수의 값이 작아지는 방향으로 가중치 매개변수를 갱신한다.
- 가중치 매개변수의 기울기를 이용하고 기울어진 방향으로 가중치의 값을 갱신하는 작업을 반복한다.
'Books > 밑바닥부터 시작하는 딥러닝1' 카테고리의 다른 글
| [밑시딥1] Chapter4 신경망 학습(1) (0) | 2023.08.05 |
|---|---|
| [밑시딥1] Chapter3 신경망 (0) | 2023.08.05 |
| [밑시딥1] Chapter2 퍼셉트론 (0) | 2023.08.03 |
해당 포스팅은 <밑바닥부터 시작하는 딥러닝1> 책을 기준으로 하며, 공부 기록 목적으로 작성되었습니다.
기울기
모든 변수의 편미분을 벡터로 정리한 것을 기울기라고 한다. 기울기는 다음과 같이 구현할 수 있다.
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # x와 형상이 같고 모든 원소가 0인 배열을 생성
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h) 계산
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h) 계산
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val
return grad넘파이 배열의 x의 각 원소에 대해서 수치 미분을 구한다.
기울기 그림은 그림 4-9처럼 방향을 가진 벡터(화살표)로 그러진다. 기울기가 가리키는 쪽은 각 장소에서 함수의 출력 값을 가장 크게 줄이는 방향이다.
경사법(경사 하강법)
기계학습 문제 대부분은 학습 단계에서 최적의 매개변수를 찾아낸다. 신경망 역시 최적의 매개변수를 학습시에 찾아야 한다. 여기서 최적은 손실 함수가 최솟값이 될 때의 매개변수 값이다. 이런 상황에서 기울기를 잘 이용해 함수의 최솟값을 찾으려는 것이 경사법이다.
각 지점에서 함수의 값을 낮추는 방안을 제시하는 지표가 기울기인데 기울기가 가리키는 곳에 함수의 최솟값이 있는지, 그 쪽이 정말고 나아갈 방향인지는 보장할 수 없다. 실제로 복잡한 함수에서는 기울기가 가리키는 방향에 최솟값이 없는 경우가 대부분이다.
경사법은 현 위치에서 기울어진 방향으로 일정 거리만큼 이동하고 이동한 곳에서 기울기를 구하고 또 기울어진 방향으로 나아가기를 반복하는 방법이다. 경사법은 기계학습 최적화, 특히 신경망 학습에 많이 사용한다.
경사법은 최솟값을 찾는 경우 경사 하강법, 최댓값을 찾는 경우 경사 상승법이라고 한다. 경사법을 수식으로 나타내면 다음과 같다.
식 4.7에서 η(eta, 에타)는 갱신하는 양을 의미한다. 이를 신경망 학습에서는 학습률이라고 한다. 한 번의 학습으로 얼마만큼 학습해야 할지 매개변수 값을 얼마나 갱신하느냐를 정하는 것이 학습률이다.
학습률 값은 0.01이나 0.001 등 미리 특정 값으로 정해두어야 하는데 이 값이 너무 크거가 작으면 좋은 장소를 찾아갈 수 없다. 학습률이 너무 크면 큰 값으로 발산해버리고, 반대로 너무 작으면 거의 갱신되지 않은 채 학습이 끝나버린다. 따라서, 학습률 값을 변경하면서 올바르게 학습하고 있는지를 확인하면서 진행해야 한다.
경사 하강법은 다음과 같이 간단하게 구현할 수 있다.
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x인수 f는 최적화하려는 함수, init_x는 초깃값, lr은 learning rate, step_num은 경사법에 따른 반복 횟수를 뜻한다. 함수의 기울기는 numerical_gradient(f, x)로 구하고 그 기울기에 학습률을 곱한 값으로 갱신하는 처리를 step_num번 반복한다.
학습률 같은 매개변수를 하이퍼파라이머라고 한다. 가중치와 편향 같은 신경망의 매개변수와는 성질이 다른 매개변수로 사람이 직접 설정해야 한다. 여러 후보 값 중에서 시험을 통해 가장 잘 학습하는 값을 찾는 과정이 필요하다.
신경망에서의 기울기
신경망 학습에서는 가중치 매개변수에 대한 손실 함수의 기울기를 구해야 한다. 예를 들어, 형상이 2*3, 가중치가 W, 손실 함수가 L인 신경망이 있을 때, 경사는 식 4.8의 두 번째 식으로 나타낼 수 있다. 이의 각 원소는 각각의 원소에 관한 편미분이다.
1행 1번째 원소는 w11을 조금 변경했을 때 손실 함수 L이 얼마나 변화하느냐를 의미한다. 여기서 중요한 점은 식 4.8의 두 행렬의 형상이 2*3로 같다는 것이다.
실제로 기울기를 구하는 코드는 다음과 같다.
import sys, os
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
# softmax, cross_entropy_error, numerical_gradient는 가져다 사용
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 정규분포로 초기화
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
# def f(W): return net.loss(x, t)
f = lambda w: net.loss(x, t)
dW = numerical_gradient(f, net.W)추가 작성 예정
학습 알고리즘 구현하기
2층 신경망 클래스 구현하기
미니배치 학습 구현하기
시험 데이터로 평가하기
정리
- 기계 학습에서 사용하는 데이터셋은 훈련 데이터와 시험 데이터로 나눠 사용한다.
- 훈련 데이터로 학습한 모델의 범용 능력을 시험 데이터로 평가한다.
- 신경망 학습은 손실 함수를 지표로, 손실 함수의 값이 작아지는 방향으로 가중치 매개변수를 갱신한다.
- 가중치 매개변수의 기울기를 이용하고 기울어진 방향으로 가중치의 값을 갱신하는 작업을 반복한다.
'Books > 밑바닥부터 시작하는 딥러닝1' 카테고리의 다른 글
| [밑시딥1] Chapter4 신경망 학습(1) (0) | 2023.08.05 |
|---|---|
| [밑시딥1] Chapter3 신경망 (0) | 2023.08.05 |
| [밑시딥1] Chapter2 퍼셉트론 (0) | 2023.08.03 |