
만약 내가 찍은 일상사진에 고흐 혹은 피카소의 작품 스타일을 적용하고 싶다면 어떻게 해야 할까?


인공지능의 가장 기본적인 내용으로 생각해 보자면 일반적인 사진과 미술 작품 스타일의 그림 여러 쌍을 supervised learning으로 학습시킬 수 있을 것이다.
하지만, 생각해 보면 사진과 미술 작품이 쌍으로 존재하는 데이터셋을 찾기란 쉽지 않다. 사실 거의 없다고 봐도 무방하다.
그렇다면 어떤 방식을 이용해서 유명한 화가의 스타일을 내 사진에 적용할 수 있을까?
CycleGAN을 이용하면 가능하다.
CycleGAN을 이용하면 다음 그림과 같이 unpaired 된 도메인 간 style transfer가 가능하다.

CycleGAN은 'Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks' 논문에서 제안된 GAN을 말한다.
CycleGAN의 핵심내용을 논문 내용 순서대로 설명하고자 한다.
1. Introduction
위에서 언급했듯이 이 논문에서는 쌍을 이루는 입력-출력 예제 없이 도메인 간 변환을 학습할 수 있는 알고리즘에 대해서 설명한다.
그러기 위해서 도메인 사이에 관계가 있다고 가정하고 그 관계를 찾을 때 도메인 set 수준의 supervision을 사용할 수 있다고 가정한다.
수식으로 설명하면 $G: X \rightarrow Y$, $\hat{y} = G(x)\quad (x \in X)$ 라고 할 때
$ \hat{y} $ 이 $ y $ 와 구분 가능하지 않도록 adversary 하게 훈련을 진행한다.
(adversary 하게 훈련하는 방식은 GAN 논문에서 등장하는 핵심내용이다.)
이렇게 훈련을 시켜주면 output $ \hat{y} $ 의 distribution이 $P_{data}(y)$ distribution과 동일하게 되고,
이때 optimal 한 G는 X를 Y에 가까운 $ \hat{y} $ 으로 translate을 가능하게 한다.
하지만, 이것인 단일 x가 y로 개별적으로 pairing이 된다는 것을 의미하지는 않는다. 다음과 같은 이유 때문인데,
- $ \hat{y} $ distribution을 만드는 G는 매우 다양하다.
- adversarial object를 단독으로 optimize 하는 것은 어렵다.
위 이유 때문에 이 논문에서는 "cycle consistent" 속성이 꼭 필요하다고 말한다.
예를 들어, "Hello."를 한국어로 번역하면 "안녕."가 되는데, 이를 다시 영어로 번역했을 때 원문인 "Hello."가 나와야 한다는 것이다.
따라서, cycle consistent loss를 추가해서 $ F(G(x)) $ 는 $ x $ 에 가까워지게, $ G(F(y)) $ 는 $ y $ 에 가까워지도록 학습한다.
2. Related work
이 논문은 GAN기반이기 때문에 원리를 아주 간단하게만 짚고 넘어가고자 한다.
GAN
GAN(Generative Adversarial Networks)는 두 개의 신경망이 서로 경쟁하며 학습하는 모델이다.
- 생성기 (Generator): 랜덤한 노이즈에서 진짜 같은 이미지를 만든다.
- 판별기 (Discriminator): 이미지를 보고 진짜인지 가짜인지 구분한다.
작동 원리
- 생성기는 가짜 이미지를 만들어 판별기를 속이려 한다.
- 판별기는 진짜 이미지와 가짜 이미지를 구분하려 한다.
- 이 과정이 반복되면서 생성기는 점점 더 진짜 같은 이미지를 만들게 된다.
뒤에 related work에서 언급한 논문에 기반이 되는 내용도 간단히만 설명하고자 한다.
Image-to-Image Translation
기존에는 paired image를 통한 image-to-image translation 연구가 많이 진행되었는데, 논문에서는 기존 연구와 달리 독립적인 입력 예제만으로 이미지-이미지 변환을 학습한다.
Unpaired Image-to-Image Translation
Bayesian framework를 비롯한 기존 방식을 몇 가지 소개하고
이와 달리 논문의 공식은 입출력 사이에 미리 정의된 task-specific function을 의존하지도 않고, 입출력이 동일한 low-dimension embedding space에 있어야 한다고 가정하지도 않아서 범용적인 solution이 될 수 있을 것이라고 말한다.
Cycle Consistency
본 연구는 transitivity을 활용해 G와 F의 consistency을 유지하는 loss을 도입하고 있다고 말하며, 유사한 몇 가지 연구들을 언급하였다.
Neural Style Transfer
Neural Style Transfer는 한 이미지의 내용을 다른 이미지의 스타일과 결합해 새로운 이미지를 만드는 반면, 본 연구는 두 이미지 컬렉션 간의 매핑을 학습해 다양한 작업에 적용할 수 있다고 언급하였다.
3. Formulation
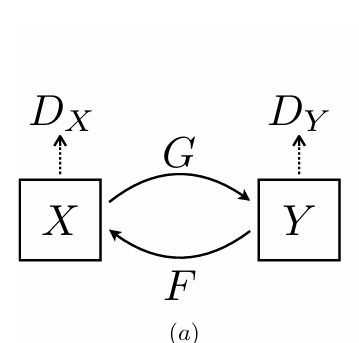
모델은 위 그림과 같이 $G: X \rightarrow Y$ , $\quad F: Y \rightarrow X$ 두 가지 mapping 과정이 포함된다.
그래서 discriminator도 $D_X$, $D_Y$ 두 개다.
$D_X$는 $X$ 도메인의 real image $x$와 translated image $F(y)$를 구분하는 역할이고, $D_Y$는 $Y$ 도메인의 real image $y$와 translated image $F(x)$를 구분하는 역할이다.
objective는 두 개의 term을 포함한다.
1. adversial losses: 생성된 이미지의 distribution을 target 영역의 데이터 distribution 일치시키기 위한 loss
2. cycle consistency losses: 학습된 매핑 G와 F가 서로 모순되지 않도록 하기 위한 loss
3.1. Adversarial Loss
$G$가 $x$를 도메인 $X$에서 도메인 $Y$로 변경하는 Generator, $D_Y$가 도메인 $Y$의 real image $y$와 $G$가 생성한 $G(x)$를 구분하는 Discriminator를 나타낸다.
$G$는 $D_Y$가 $G(x)$와 $y$를 구분하지 못하도록 $y$와 가까운 이미지를 생성하도록 학습되고,
$D_Y$는 $G(x)$와 $y$를 잘 구분해 낼 수 있는 방향으로 학습이 이루어진다.
이를 수식에 적용하면 $G$는 objective를 minimize, $D_Y$는 maximize 하는 방향으로 학습이 진행된다.
예를 들어 생각하면 편하다.
우선 GAN에서 Discriminator가 real image를 1, fake image를 0으로 판단하기 때문에 아래 loss와 함께 보면
$D_Y$ 입장에서 $D_Y(y)$는 1에 가까워야 하고, $D_Y(G(x))$는 0에 가까워야 한다. 따라서, objective를 maximize 하는 방향으로 학습이 진행해야 한다는 것이다. $G$는 이와 반대로만 생각하면 된다.
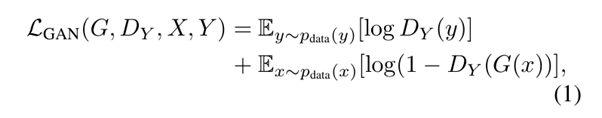
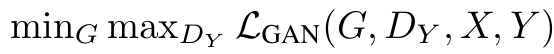
F는 도메인을 Y에서 X로 변경하는 것뿐 G와 역할은 똑같으므로 다음 식이 적용된다.
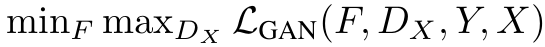
3.2. Cycle Consistency Loss
Introduction에서도 언급했듯이, 큰 용량의 네트워크는 주어진 입력 이미지를 목표 이미지 도메인의 어떤 랜덤한 이미지로도 매핑할 수 있다. 즉, 네트워크가 출력 분포를 목표 분포와 일치시키기만 하면 되기 때문에, Adversarial Loss만으로는 특정 입력이 원하는 특정 출력으로 변환되도록 보장할 수 없다.
이를 위해서 추가적인 제약이나 손실 함수가 필요하고 이를 Cycle Consistency Loss로 정의한다.
cycle consistency loss에서는 forward cycle consistency $x \rightarrow G(x) \rightarrow F(G(x)) \approx x$ 와 backward cycle consistency $y \rightarrow F(y) \rightarrow G(F(y)) \approx y$ 를 만족하도록 loss term을 구성한다.
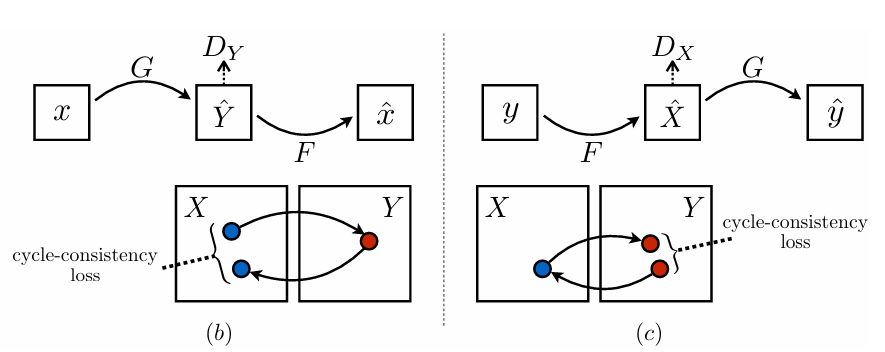
그림으로 표현하면 Figure 3의 (b), (c) 이고, 식으로 표현하면 (2) 와 같다.
이때 adversarial loss를 사용하려 했는데 성능이 더 좋아지지 않아 L1 norm을 사용했다고 한다.
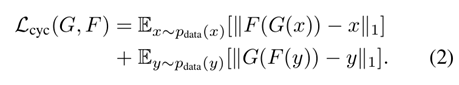
Figure 4에서 input image를 다른 도메인으로 translate하고 다시 복원한 이미지의 예시를 보여주고 있다.

3.3. Full Objective
Full objective는 위에서 설명한 adverserial loss 두 term과 cycle consistency loss term으로 이루어진다.
여기서 λ는 두 objective의 상대적 중요성을 제어하는 가중치 역할을 한다.
(autoencoder를 간단히 설명하면 입력 데이터를 압축하고 다시 복원하는 신경망이다.)
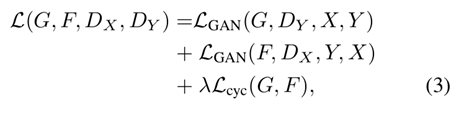
논문에서는 이 내용을 2개의 autoencoder를 학습하는 모델로 볼 수 있다고 언급한다. 2개는 다음과 같다.
- $ F \circ G: X \to X $ : 첫 번째 오토인코더는 입력 도메인 X의 이미지를 다시 X로 복원한다. 중간에 다른 도메인 Y로 변환된 표현을 사용
- $ G \circ F: Y \to Y $ : 두 번째 오토인코더는 입력 도메인 Y의 이미지를 다시 Y로 복원한다. 이 역시 중간에 다른 도메인 X로 변환된 표현을 사용
위 과정은 adversarial autoencoders와 유사하며 특정 target 분포에 맞추기 위해 적대적 손실(adversarial loss)을 사용하여 학습한다. 이 경우, 첫 번째 오토인코더의 목표 분포는 도메인 Y의 분포이다. 쉽게 말해, X 도메인의 데이터를 Y 도메인의 형태로 변환하면서 원래의 형태로 다시 복원하는 방법을 학습하는 것이다.
implementation과 result는 간단히 정리하는 방식으로 서술하였다.
4. Implementation
Network Achitecture
Achitecture는 다음과 같다.
논문에서 128 × 128 과 256 × 256 일 때는 나눠서 설명했는데 128 × 128 일 때만 확인하면 우선 생성 네트워크의 경우 다음과 같이 구성되어 있다.
- convolution layer와 residual blocks 사용
- c7s1-64, d128, d256, R256, R256, R256, R256, R256, R256, u128, u64, c7s1-3
- c7s1-k: 7 × 7 Convolution-InstanceNorm ReLU layer with k filters and stride 1.
- dk: 3 × 3 Convolution-InstanceNorm-ReLU layer with k filters and stride 2 (Reflection padding 사용)
- Rk: 두 개의 3 × 3 convolutional layers로 구성된 residual block , 동일한 필터 수 사용
- uk: 3 × 3 fractional-strided-Convolution InstanceNorm-ReLU layer with k filters and stride 1
- c7s1-64, d128, d256, R256, R256, R256, R256, R256, R256, u128, u64, c7s1-3
- Instance Normalization 적용
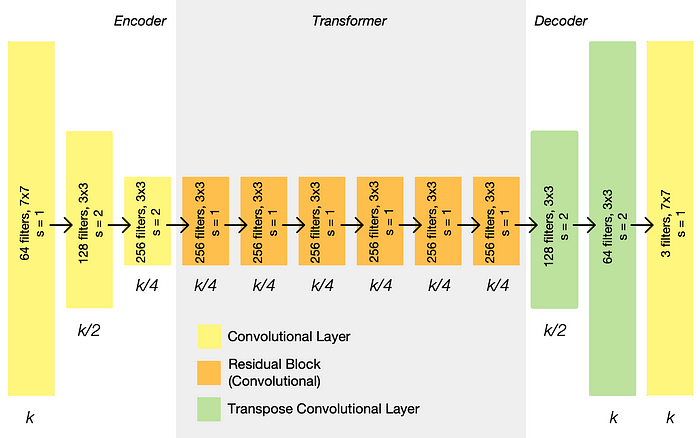
위에서 볼 수 있듯이 인코더 단계에서 representation 크기가 줄어들고, 트랜스포머 단계에서 일정하게 유지되며, 디코더 단계에서 다시 확장된다. 각 레이어가 출력하는 representation 크기는 입력 이미지 크기인 k를 기준으로 그 아래에 나열되며, 각 레이어에는 필터 수, 필터의 크기, 보폭이 나열되어 있습니다. 각 레이어 뒤에는 instance normalization 및 ReLU activation이 이어진다.
Discriminator 네트워크의 경우 다음과 같다.
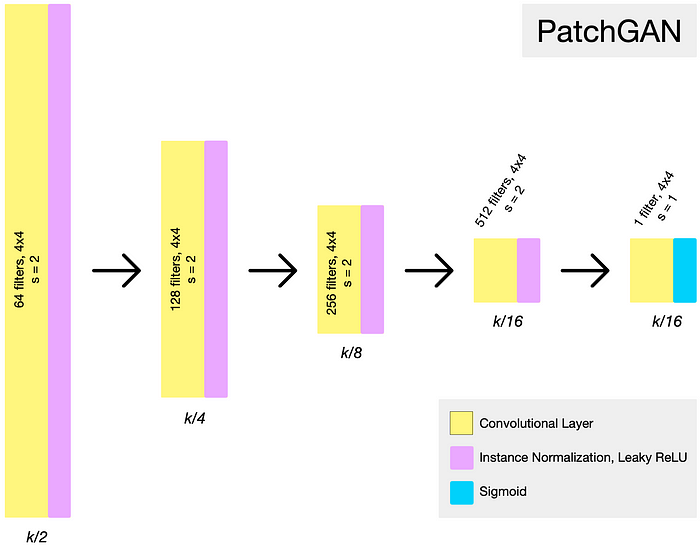
- 70 × 70 PatchGANs 사용
- PatchGAN: 이미지를 입력받아 이미지의 해당 '패치'가 '실제'일 확률을 나타내는 확률 행렬을 생성하는 완전 컨볼루션 네트워크
- C64 - C128 - C256 - C512
- Ck: Convolution-InstanceNorm-LeakyReLU (slope: 0.2) layer with k f ilters and stride 2.
Training details
- 손실 함수 변경:
- $ \mathcal{L}_{GAN} $ 손실 함수를 negative log likelihood 에서 least-squares loss 로 변경하여 훈련의 안정성 및 결과 품질 향상
- 훈련 과정:
- $G$를 $\mathbb{E}_{x \sim p_{data}(x)}[(D(G(x)) - 1)^2]$를 최소화하도록 훈련하고,
$D$를 $\mathbb{E}_{y \sim p_{data}(y)}[(D(y) - 1)^2] + \mathbb{E}_{x \sim p_{data}(x)}[D(G(x))^2]$를 최소화하도록 훈련한다.
- $G$를 $\mathbb{E}_{x \sim p_{data}(x)}[(D(G(x)) - 1)^2]$를 최소화하도록 훈련하고,
- 모델 진동(oscillation) 감소:
- 최신 generator가 생성한 이미지 대신, 이전에 생성된 50개의 이미지를 사용하여 discriminator update.
- 실험 설정:
- equation 3에서 $\lambda = 10$ 으로 설정.
- Adam optimizer 사용, batch size = 1.
- learning rate 0.0002로 처음부터 훈련.
- 처음 100 epoch 동안 learning rate 유지, 다음 100 epoch 동안 linear하게 0으로 감소
5. Results
5.1. Evaluation
pix2pix와 동일한 evaluation dataset, metrics 사용
5.1.1 Evaluation Metrics
- AMT Perceptual Studies: 생성된 이미지의 현실성을 평가하기 위해 Amazon Mechanical Turk(AMT)에서 "진짜 vs 가짜" 지각 연구 수행
- 참가자들은 진짜 사진 또는 지도와 가짜 이미지(알고리즘 또는 기준선에서 생성된)를 쌍으로 보여주고 진짜라고 생각하는 이미지를 클릭하도록 요청
- 각 세션의 첫 10회는 연습이며 피드백을 제공하고 나머지 40회는 각 알고리즘이 참가자를 속이는 비율을 평가
- 각 세션은 하나의 알고리즘만 테스트하며, 참가자는 한 세션만 완료 가능
- FCN Score: 인간 실험이 필요 없는 자동 정량적 평가 지표 제공
- Cityscapes 라벨→사진 작업에서 사용.
- 생성된 사진이 사전 학습된 FCN(완전 합성곱 신경망)에 의해 얼마나 잘 해석되는지 평가
- FCN이 생성된 사진에 대해 예측한 라벨 맵을 입력된 진짜 라벨과 비교
- Semantic Segmentation Metrics: photo→label 작업의 성능 평가
- Cityscapes 벤치마크의 표준 지표 사용
- 지표: 픽셀 당 정확도(per-pixel accuracy), 클래스 당 정확도(per-class accuracy), 평균 클래스 교차-연합 (mean class Intersection-Over-Union, Class IOU).
5.1.2 Baselines
CoGAN, SimGAN, Feature loss + GAN, BiGAN/ALI, pix2pix
5.1.3 Comparison against baselines
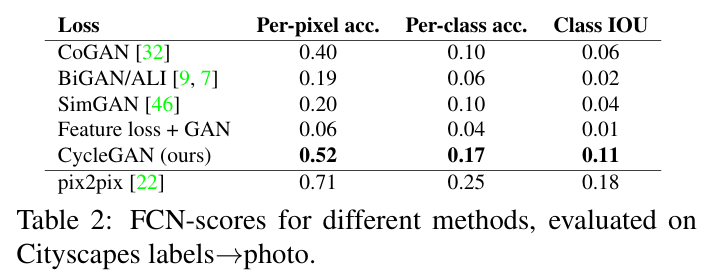
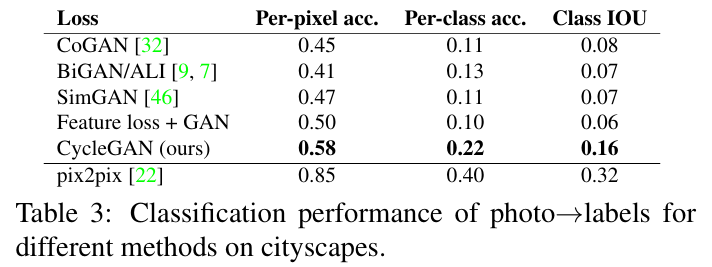
이 부분은 역시 CycleGAN이 다른 baseline 모델보다 성능이 좋음을 그림과 표로 보여주는 부분이다.



5.1.4 Analysis of the loss function
5.1.4 에서는 loss function에 대한 ablation study 결과를 보여준다.
GAN loss, cycle-consistency loss를 가지고 다양하게 실험하여 cycleGAN loss 결과가 가장 좋음을 보여준다.
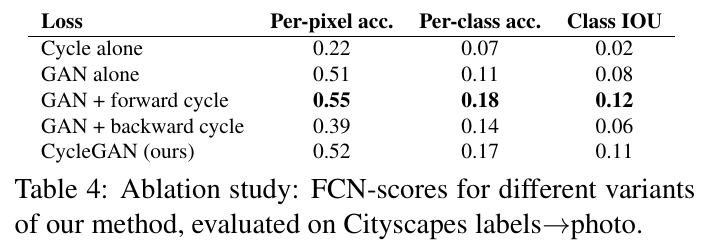
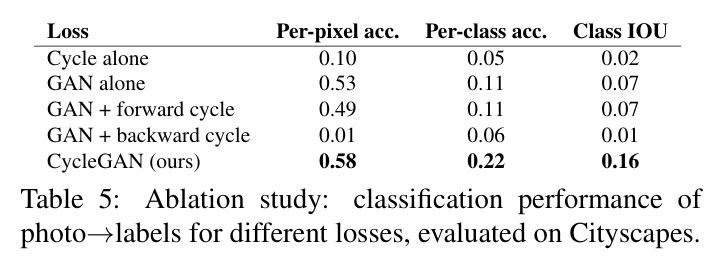
5.1.5 Image reconstruction quality
5.1.6 Additional results on paired datasets

5.2. Applications
5.2 에서는 paired 훈련 데이가 존재하지 않는 다양한 응용 분야에 대한 시연 내용을 보여준다. (Figure 10~16)
- Collection style transfer
- Object transfiguration
- Season transfer
- Photo generation from paintings
- Photo enhancement
6. Limitations and Discussion
하지만, CycleGAN에 모든 task에서 성공한 것은 아니다.
이 논문에서는 색상과 텍스처 변환 작업에서는 성공적인 결과를 얻었지만, 기하학적 변화를 요구하는 작업에서는 실패하는 경우가 많다고 설명한다. 대표적인 예로 개를 고양이로 변환하는 작업의 실패를 언급한다.
또한, 훈련 데이터셋의 한계(ImageNet 데이터셋에 사람이 말을 타고 있는 이미지가 없음)로 인해 말에서 얼룩말로 변환하는 작업도 제대로 이루어지지 않았다고 한다.

짝지어진 데이터로 훈련된 결과와 비교할 때 성능 차이가 있으며, 이 격차를 줄이기 위해서는 약한 의미적 supervision이 필요할 수 있다고 한다. 따라서, 미래 연구에서는 약한 supervision이나 semi supervisied learning을 통합하여 더 강력한 translators를 개발하고, unpaired 데이터를 최대한 활용하는 것이 중요하다고 결론짓고 있다.
Reference
https://arxiv.org/abs/1703.10593?context=cs.CV
'ML & DL > GAN' 카테고리의 다른 글
| StyleGAN2-ADA 학습 튜토리얼 (AHFQ-v2 Dataset 사용) (0) | 2024.10.27 |
|---|---|
| loss 값이 nan이 되는 이유 및 오류 해결(feat. StyleGAN) (0) | 2024.10.22 |
| CycleGAN 모델 파라미터 정리 (0) | 2024.07.31 |
| 하나하나 쉽게 설명하는 StyleGAN 논문 리뷰 (4) | 2024.06.17 |