
오늘은 StyleGAN이 등장한 논문
"A Style-Based Generator Architecture for Generative Adversarial Networks"을 리뷰해보려고 합니다.
이 글은 나동빈님의 https://www.youtube.com/watch?v=HXgfw3Z5zRo 리뷰 영상을 참고하여 작성하였습니다.
StyleGAN은 이미지 생성 네트워크 중에서 뛰어난 성능을 보이는 아키텍처를 제안합니다.
우선 StyleGAN을 등장시킨 Style-Based Generator Architecture for Generative Adversarial Networks의 주요 contribution은 다음과 같습니다.
- PGGAN을 기반으로 style transfer 분야의 아이디어를 활용해 고성능의 generator를 만들어냅니다. 본 연구는 generator architecture에 초점이 맞춰진 연구로 discriminator에는 변화를 주지 않았습니다.
- 스타일 정보의 분리를 가능하게 해서 서로 다른 특징들을 보다 쉽게 컨트롤할 수 있게 합니다.
- style끼리의 disentanglement를 측정하는새로운 metric을 도입합니다.
- perceptual path length
- linear separability
- 1024x1024 크기의 고해상도 사람 얼굴 dataset인 FFHQ를 배포하고 누구나 다운로드받아 학습을 진행할 수 있도록 했습니다.
그럼 본격적으로 논문 순서대로 StyleGAN에 대해서 리뷰해 보도록 하겠습니다.
1. Introduction
Introduction에서는 위에서 설명한 contribution에 대한 간단한 설명을 진행합니다.
<1> PGGAN + style transfer → 고성능의 generator 제안
원본 GAN 논문 이후, 특히 이미지 생성 분야에서 다양한 기술들이 제안되어 왔습니다.
그중 PGGAN 또는 ProGAN은 고해상도 이미지 생성에서 주목받았지만, GAN 내부의 동작 원리는 여전히 블랙박스처럼 느껴졌습니다. 이미지 생성 시 stochastic feature를 제어하는 방법이나 latent space에 대한 연구도 부족했습니다.
일반적으로 서로 다른 두 이미지 사이의 latent vectors에서 interpolation을 수행해 네트워크 성능을 평가했지만, 정량적인 평가가 어려웠습니다.
본 논문은 generator 설계를 개선하기 위해 style transfer 아이디어를 적용하여 StyleGAN을 개발했습니다. StyleGAN은 이미지의 해상도를 점차 키워가며 다양한 스타일을 적용해 이미지를 생성하는 방식입니다. 학습된 상수에서 시작해 여러 블록을 거치며 해상도가 커지고, 마지막에는 RGB 컬러로 변환해 결과 이미지를 만듭니다. 각 블록마다 스타일 정보를 입력받아 많은 스타일이 반영되며, stochastic variation도 제어 가능합니다.
주목할 점은, 이러한 기능들은 모두 generator를 수정하여 얻은 결과이며, discriminator나 loss function은 거의 수정하지 않았다는 것으로 본 논문의 핵심 기여입니다.
<2> 서로 다른 특징들을 보다 컨트롤
일반적으로 generator는 어떠한 랜덤한 latent code를 받아서 다양한 이미지를 만들 수 있는데, 보통은 uniform distribution이나 gaussian distribution에서 하나의 noise vector를 뽑아서 입력으로 넣는 방식을 사용합니다.
본 논문에서는 latent code를 한 번 intermediate latent space로 보내준 뒤, 그 space에서 generator의 input으로 들어갈 수 있도록 만듭니다.
그 이유는 다음과 같습니다.
기본적으로 입력 latent space가 트레이닝 데이터의 확률 밀도 함수를 따를 수밖에 없기 때문에, 단순하게 가우시안 분포에서 샘플링한 노이즈를 입력으로 넣게 되면 어느 정도 entanglement가 발생할 수 밖에 없습니다.
반면, intermediate space로 한 번 매핑한 뒤, 거기에서 실제 네트워크에 입력하게 되면 특정한 분포를 꼭 따라야 한다는 제약이 사라지기 때문에 disentanglement 측면에서 이점을 얻을 가능성이 높아진다는 것입니다.
<3> 새로운 metric을 도입해서 style끼리의 disentanglement 측정
본 논문에서는 perceptual path length와 separability 이 두 가지 metric을 제안했습니다.
이 metric은 각각의 특징들이 얼마나 선형적으로 잘 분리되면서 그리고 interpolation 과정에서 자연스러운 이미지를 만들 수 있는지에 대한 적절한 평가 지표로서 사용될 수 있습니다.
본 논문에서는 실제로 이러한 metric을 활용했을 때, 제안한 generator architecture는 훨씬 linear하게 동작하면서 representations이 서로 덜 얽혀서 특징들을 컨트롤하기 쉽게 만들었다고 주장합니다.
<4> 고해상도 사람 얼굴 dataset인 FFHQ를 배포
마지막으로 본 논문에서는 지금은 잘 알려진 고해상도 얼굴 dataset FFHQ를 배포해서 많은 사람들이 고해상도 이미지 데이터셋으로 학습을 진행할 수 있도록 했습니다.
2. Style-based generator
2장에서는 제안한 generator architecture를 설명하며, 기존의 어떤 방법과 어떤 방식이 다른지 설명하는 방식으로 논문을 전개합니다.
일반적으로 이전까지의 generator는 하나의 latent vector를 넣을 때, 말 그대로 latent vector에 따라서 다양한 이미지가 생성될 수 있도록 만들었습니다. 그러나 본 네트워크에서는 별도로 스타일 정보를 layer를 거칠 때마다 따로 넣어줍니다. 따라서, 처음부터 latent 코드로 시작하지 않고 하나의 학습된 상수(const 4x4x512)를 그 자체로서 generator에 입력으로 넣어줄 수 있도록 하고, 그러한 학습된 상수가 convolution layer를 거치는 과정에서 스타일에 대한 정보를 입력받아 다양한 이미지를 생성할 수 있도록 구성되어 있습니다.
즉, 일반적인 네트워크와 다른 점은 generator의 입력으로 들어가는 것이 일반적인 latent vector가 아니라 학습된 하나의 상수 이미지로서 입력된다는 점입니다.
또한 중요한 특징 중 하나는 별도의 Gaussian distribution이나 uniform distribution에서 noise를 샘플링하여 바로 넣는 것이 아니라, 별도의 비선형 매핑을 통해 W vector로 바꾸고, 이 W vector가 실제 입력으로 들어갈 수 있도록 만드는 것입니다.
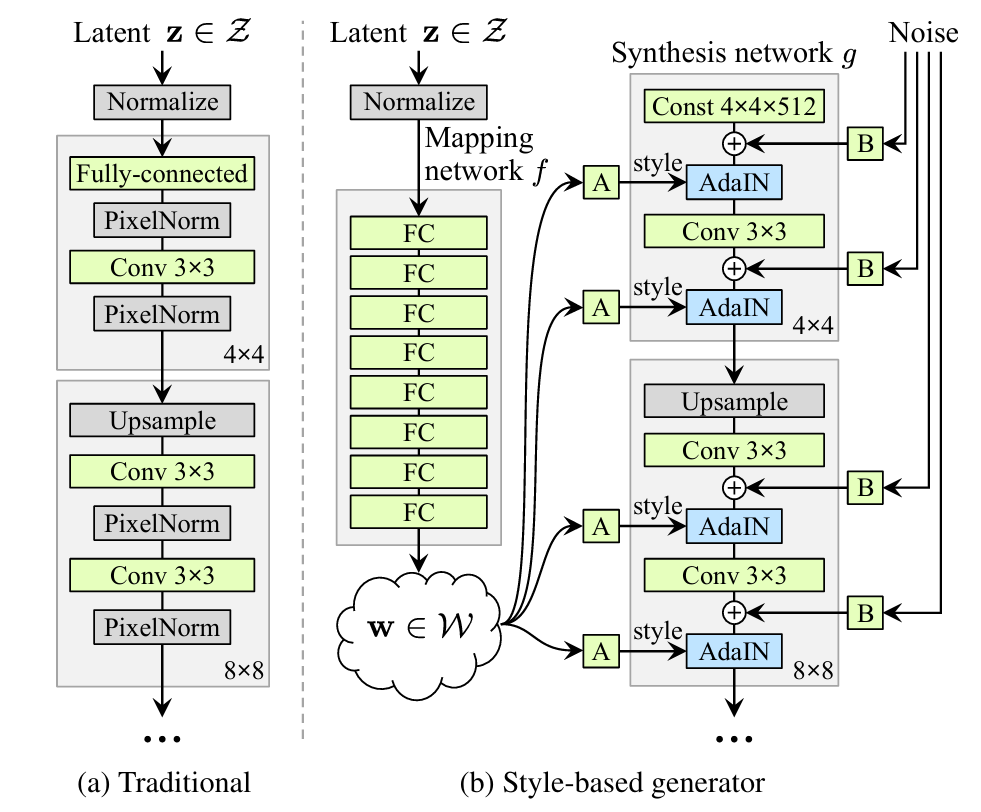
Figure 1을 확인해 보시면, 왼쪽에 있는 architecture는 일반적인 general architecture로 논문의 baseline architecture인 PGGAN의 architecture입니다. PGGAN에서는 특정한 분포에서 하나의 latent vector인 Z를 바로 샘플링을 해서 정규화를 거친 뒤에 입력으로 들어갑니다.
그러나 본 논문에서 제안한 StyleGAN은 이러한 latent vector인 Z를 뽑은 뒤에 하나의 매핑 네트워크를 거쳐서 W vector로 바꾸고, 이 W vector가 입력으로 들어갈 수 있는 형태로 구성됩니다.
W vector를 만든 뒤에는 W vector를 각각의 block마다 두 번씩 별도의 affine transtform을 거쳐 입력될 수 있도록 만듭니다. 그 부분이 'A' 부분입니다.
systhesis network g는 4x4 짜리 너비와 높이를 가진 텐서로부터 출발해서, 각 block을 거칠수록 너비와 높이는 두 배로 증가하게 되어 마지막 결과 이미지가 1024x1024가 되고 block은 총 9개 들어가게 됩니다.
그런 9개의 block마다 두 번씩 스타일 벡터가 들어가기 때문에 결과적으로 generator에 들어가는 스타일 벡터는 18x512차원짜리 하나의 행렬이 됩니다. 즉 block이 9개고 2번씩 들어가니까 스타일 벡터가 총 18개로 분리되어 들어간다고 이해할 수 있습니다.
또한, 본 논문에서는 한 명의 사람 이미지에서 조금씩 확률적으로 바뀔 수 있는 정보인 주근깨나 머릿결, 피부 컨디션과 같은 stochastic variation을 처리할 수 있도록 하기 위해 별도의 noise vector 또한 입력으로 받습니다. Figure (b)의 'B' 부분으로 마찬가지로 각 block마다 2개씩 들어가는 형태가 유지됩니다.
여기서 A의 경우 하나의 512차원짜리 W 벡터가 있을 때 거기에서부터 스타일 정보를 가져올 수 있도록 만드는데요, 이때 style transfer network는 일반적으로 AdaIN이라는 하나의 normalization layer를 사용하여 하나의 feature에 대한 정보를 입력받은 style의 statistics을 이용해서 하나의 feature에 대한 statistics을 바꿀 수 있도록 만듭니다.
정확히는 scaling과 bias를 적용함으로써 convolution 연산을 통해 얻은 feature output의 통계적인 정보를 바꾸는 방식으로 style을 입힐 수 있습니다.
noise에 대한 정보는 항상 convolution 연산 이후에 들어가고, 그렇게 얻어진 feature map의 각 channel에 대해서 통계적인 정보를 변경할 수 있도록 style 정보를 받아서 AdaIN layer를 거쳐 해당 style을 적용할 수 있도록 만듭니다. 이러한 과정을 반복해서 그럴듯하면서도 다양한 결과 이미지를 얻을 수 있는 것입니다.
Figure 1 과정을 정리하면 먼저 input을 latent vector를 w space의 한 vector로 바꿔주고 별도의 affine layer를 거쳐서 style 정보를 얻은 뒤에 AdaIN layer를 거쳐서 각각의 convolution layer를 거친 결과에 대해서 style 정보를 적용할 수 있도록 만듭니다.
B 같은 경우는 noise가 적용될 수 있도록 하기 위한 affine transformation이고요. 또한 mapping network는 8개의 layer로 구성되어 512차원의 input을 다른 512차원의 W ouput으로 만들어주는 network입니다.
또한 generator는 18개의 layer로 구성되며 총 9개의 block이 존재하므로 각 block마다 2개의 convolution layer로 구성된다고 이해하시면 되겠고요, 4x4에서 1024x1024까지 저해상도에서 고해상도로 점차 해상도를 늘려가는 방식으로 이미지를 만든다고 보시면 되겠습니다. 한 번에 저해상도에서 고해상도 이미지를 만들기는 어렵기 때문에 일반적으로 여러 개의 block을 거쳐서 단계적으로 이미지 해상도를 증가시키는 방법을 사용하는 것입니다.
마지막에는 channel 사이즈가 얼마가 됐든 간에 결과 이미지를 만들 수 있어야 되기 때문에 RGB color를 가질 수 있는 3차원의 tensor가 될 수 있도록 만듭니다. 흔히 이를 to RGB layer라고 부르며 이러한 layer는 이전 논문의 PGGAN 논문에서도 사용되었던 technique이고 본 논문 또한 이러한 방식을 그대로 쓴다고 말하고 있습니다.
그래서 전통적인 생성자에 비교했을 때 parameter 수는 그렇게까지 많이 증가하지 않으면서 성능은 훨씬 개선될 수 있기 때문에 효과적인 architecture를 가질 수 있습니다.
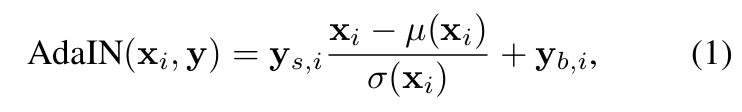
위 식이 Adaptive Instance Normalization 즉 AdaIN에 대한 식입니다.
AdaIN layer는 일반적으로 feed-forward 방식의 style transfer network에서 효과적으로 사용되는 정교한 layer이며, 원래는 한 장의 content 이미지가 있을 때 다른 style 이미지로부터 그 style 정보를 받아와서 AdaIN을 거쳐서 content 이미지의 feature statistics를 변경함으로써 style transfer를 수행할 수 있도록 하는 방법입니다.
여기서 x에 대해서 평균값을 빼고 standard deviation으로 나누어 주는 연산은 일반적인 정규화이고 추가적으로 scaling과 bias를 적용함으로써 feature space에서의 statistics를 변경할 수 있습니다.
아까 하나의 고정된 tensor에서부터 출발해서 layer를 거쳐가면서 결과 이미지가 된다고 했는데 그 고정된 tensor에서부터 출발한 AdaIN layer를 거치기 전 input 값이 x이고, AdaIN layer를 거쳐서 매번 style 정보가 바뀌는 내용이 바로 이 y에 의해서 control 되는 것입니다.
추가로 Instance Normalization과 Batch Normalization의 차이점이라고 한다면 Batch Normalization에서는 channel당 하나의 batch에 포함되어 있는 모든 이미지를 걸쳐서 channel 당 정규화를 수행합니다. 반면, Instance Normalization에서는 한 이미지에 대해서 각각 channel당 정규화를 수행하는 것입니다.
Instance Normalization이 훨씬 style transfer 측면에서 잘 동작한다는 것이 밝혀졌기 때문에 style transfer에 잘 활용되고 있는 것입니다.
따라서, xi는 각각의 channel당 feature map이며, 이들이 전부 개별적으로 정규화된 이후에 scaling과 bias를 적용해서 style transfer를 수행하는 방식이 적용되는 것입니다.
2.1. Quality of generated images

Table 1은 baseline architecture와 비교했을 때 본 논문에서 제안한 메소드를 적용해서 얼마나 FID 성능이 좋아지고 있는지를 보여줍니다. 여기서 FID는 생성자의 quality를 측정하기 위한 전통적인 방법입니다.
여기에 baseline architecture인 PGGAN부터 조금씩 메소드가 추가되고 있는 것이기 때문에 F가 본 논문에서 제안한 모든 기법들을 다 적용한 결과입니다.
Dataset
- CelebA-HQ: 기존에 많이 사용되었던 잘 알려진 얼굴 데이터셋 CelebA 의 고해상도 버전
- FFHQ: 본 논문에서 새롭게 배포한 데이터셋
Method
- A: baseline architecture = PGGAN
- B: 튜닝
- upsampling과 downsampling을 수행할 때 interpolation 메소드를 바꿈
- training을 더 길게
- 하이퍼 파라미터 튜닝
- C: mapping network 추가, style transfer 아이디어를 적용(= AdaIN연산 추가)
- D: 전통적인 latent vector를 입력으로 받지 않고 4x4x512 차원의 학습된 상수 tensor로부터 출발하도록 만든 것 = 고정된 상수로부터 출발하고 결과 이미지를 만들어내기까지 style을 입혀 나가는 방식 사용
- E: noise input 적용
- F: mixing regularization 사용

그래서 styleGAN을 이용해서 만들어낸 다양한 이미지는 Figure 2에 나와 있습니다. 별도로 잘 나온 것만을 선별하지 않고 style GAN 자체가 이 정도의 quality를 항상 낼 수 있다고 말하고 있습니다.
물론 일반적으로 높은 quality의 이미지를 만들기 위해서는 truncation trick을 사용되는데요. 여기에서도 마찬가지로 truncation trick을 활용해서 이미지를 뽑은 것이라고 밝히고 있습니다.
truncation trick
truncation trick이란,
하나의 GAN 모델을 학습 완료한 뒤에 샘플링을 수행할 때 그럴싸한 이미지가 잘 나올 수 있도록 더욱 평균에 가까운 이미지가 나올 수 있게 이 latent vector에 truncation을 적용한 것입니다.
학습을 완료한 후 샘플링을 수행할 때 probability density가 높은 부분에서 샘플링을 수행하면 당연히 더 그럴싸한 이미지가 나올 수 있겠지만, 모든 요소에 대해서 현실적으로 샘플링을 수행할 때는 그럴싸하지 않은 이미지 또한 만들어질 수 있기 때문에 가능하면 density가 높은 이미지에서부터 샘플링을 수행할 수 있도록 하기 위해 하나의 latent vector가 latent vector space에서 중간에 가까운 값이 될 수 있도록 잘라내기(truncation)를 수행해서 결과를 얻도록 만드는 것입니다.
3. Properties of the style-based generator
3절에서는 본격적으로 styleGAN에 대한 속성을 분석해서 명시합니다.
styleGAN architecture를 사용하면 style의 특정 subset을 바꾸는 것은 이미지의 특정한 양상을 바꾸는 효과를 낼 수 있는데, 이러한 특징을 다른 말로 localization라고 합니다.
즉 layer의 특정 부분에 대한 style을 바꾸는 것은 특정한 양상을 바꾸는 형태로 동작할 수 있습니다.
기본적으로 AdaIN 연산은 각각의 channel에 대해서 정규화를 수행하기 때문에 feature map마다 정규화를 수행한다고 할 수 있고, 매번 convolution 연산 이후에 normalization을 수행하기 때문에 각각의 style이 서로 다른 특징을 나타내도록 분리될 수 있습니다.
다시 말해 각각의 style은 하나의 convolution에 대해서 적용되고 다음 AdaIN 연산에 의해서 덮어쓰기가 수행될 수 있다는 점이 이러한 특징을 분리하는 데 더욱 기여하는 요소가 될 수 있다는 것입니다.
3.1. Style mixing
본 논문에서는 각각의 style이 더욱 localize 되어서 다른 layer에는 관여하지 않도록 만들기 위해서 즉 더욱 잘 localize시키기 위해서 style mixing이라는 technique을 제안합니다.
Table 1 F에서 추가된 method, mixing regularization과 같은 내용입니다.
방법은 간단합니다.
두 개의 latent vector가 있을 때, 학습 진행 시 단순히 한 개의 latent vector만 뽑아서 이미지를 만드는 것이 아니라 두 개의 latent vector를 서로 섞어서 이미지를 만들 수 있도록 하는 것입니다.
섞는다는 말은 crossover point를 사용한다는 것입니다.
예를 들어서 앞쪽 layer에서는 w1을, 뒤쪽 layer에서는 w2를 쓰는 방식을 사용할 수 있습니다.
여기에서 의도하는 내용은 각각 들어가는 style들이 서로 다른 style과 상관관계를 가지지 않도록 하는 것이므로
여기에서 말하는 mixing은 두 vector 간 interpolation하는 것이 아니라, 특정 앞쪽 layer까지는 vector1을 쓰고, 뒤쪽 layer부터는 vector2를 쓰는 방식을 의미합니다.
그렇게 함으로써 인접한 layer가 이러한 style끼리 서로 상관관계를 갖지 않도록 유도할 수 있습니다.
다시 말해 style mixing은 인접한 style끼리의 correlation을 줄이고 더욱 지역화될 수 있도록 만들기 위한 technique입니다. 그래서 crossover point를 설정하고, w1과 w2 vector가 교차되어 적용된 하나의 vector를 실제 학습에 사용할 수 있도록 만들어서 각각의 layer에 따른 style들이 서로 correlation이 사라질 수 있도록 유도했습니다.

Figure 3가 실제 styleGAN을 이용해서 여러 개의 이미지 사이에서 style mixing을 수행한 결과입니다.
즉 여기에서는 interpolation이라고 하기보다는 두 개의 latent vector가 있을 때 각각의 layer에 따라서 어떤 layer에서는 source B를 쓰고, 어떤 layer에서는 source A를 쓴 결과입니다.
실제로 style mixing을 수행한 결과들은 source B의 style 중에서 특정 subset과 source A의 style 중에서 그 나머지 subset을 합친 것이라는 의미입니다.
layer마다 서로 다른 latent vector로부터의 style을 사용했다라고 이해하시면 되겠습니다.
자, 그래서 source A의 특정한 정보를 source B에서부터 가져와서 style mixing을 수행한 건데요.
왼쪽에 나와있는 course, middle, fine style은 다음과 같습니다.
- Coarse Style
- 전반적인 sementic feature들을 바꿀 수 있는 style (포즈, 얼굴형, 안경 여부 등)
- 네트워크의 앞쪽 레이어에 적용되기 때문에 최종 이미지의 큰 시멘틱 요소에 큰 영향을 미친다.
- Middle Style
- 중간 수준의 특징들(헤어스타일, 눈을 뜨거나 감은 상태 등)
- 중간 스타일 정보는 5번째부터 8번째 W 벡터에 적용된다.
- Fine Style
- 작은 세부 특징들(색상, 미세한 구조 차이 등)
- 세밀한 스타일 정보는 네트워크의 뒤쪽 레이어에 적용된다. 뒤쪽 레이어에서는 영향을 미칠 수 있는 패치의 크기가 작기 때문에 세밀한 정보 위주로 바뀐다.
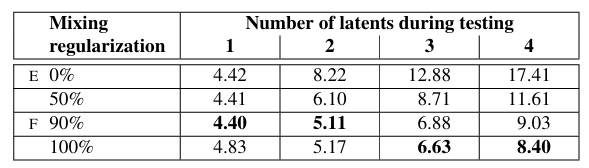
Table 2는 FID 측면에서 mixing regularization의 영향을 분석한 결과입니다.
mixing regularization을 많이 사용할수록 style mixing을 수행했을 때에도 그럴싸한 결과가 잘 나올 수 있다는 걸 보여줍니다.
3.2. Stochastic variation

이어서 stochastic variation에 대해서 분석합니다.
Figure 4는 하나의 동일한 style vector에 대해서 noise vector만 바꾼 결과들을 보여줍니다. style은 유지한 상태로 noise만 바꾸었을 때 확률적인 정보들이 조금씩 바뀌는 걸 확인할 수 있습니다.
여러 번 noise를 바꾸어서 standard deviation을 분석한 결과 그림처럼 특히 머리카락과 같은 정보가 많이 바뀌는 걸 확인할 수 있었다고 합니다.
참고로 TensorFlow나 PyTorch로 구현할 때 style 정보가 동일하게 들어오더라도 매번 noise vector는 바뀔 수 있도록 설정이 되어 있기 때문에 구현 상 style을 유지하면서 단순하게 foward만 하더라도 매번 조금씩은 다른 이미지가 만들어지는 것이 디폴트입니다.

Figure 5는 generator의 여러 레이어에서 noise input이 미치는 영향을 설명합니다.
- (a): 원래 style
- (b): noise 적용하지 않음 → 특히 머리카락과 같은 부분에서 디테일이 많이 떨어짐
- (c): fine layer에 대해서만 noise 적용 → 머리카락의 컬링과 같은 큰 스케일적인 부분에 영향
- (d): coarse layer에 대해서만 noise를 적용 → 세밀한 머리카랑 컬링, 여러 디테일적인 부분에 영향
여기에서 이러한 noise는 오직 확률적인 양상에 대해서만 영향을 미치고 전반적인 구성 및 정체성 등의 high-level 측면에는 영향을 미치지 않는다는 것을 볼 수 있습니다.
다시 말해, 이미지에 대한 high-level feature aspects는 style을 이용해서 control 할 수 있고 noise로는 control 하기 어렵다는 걸 보이고 있습니다.
또한, noise는 network의 각 layer에서 사용 가능하며, generator는 새로운 콘텐츠 도입을 위해 이를 활용하여 stochastic variation을 생성합니다.
3.3. Separation of global effects from stochasticity
그래서 본 논문에서는 w vector가 실제로 포즈를 바꾸거나 얼굴에 해당하는 정체성을 바꾸는 등 더욱더 글로벌한 효과를 가지고 있고, noise는 상대적으로 더욱 확률적인 다양성 측면에서 영향을 미칠 수 있다고 언급합니다.
4. Disentanglement studies
이어서 본 논문에서는 style GAN network의 disentanglement 측면에서도 연구를 진행했습니다.
disentanglement는 latent space를 linear sub-space를 갖도록 하는 것을 말하는 것이고, linear 하기 때문에 latent space에 존재하는 두 개의 vector를 뽑은 후, 두 vector 사이에 interpolation을 수행했을 때 훨씬 그럴싸하게 우리가 의도했던 특정한 feature만 바뀌는 방식으로 새로운 이미지를 얻을 확률이 높다는 것을 의미합니다.
특정한 factor를 바꿔서 개별적인 control이 가능하다면 여러 개의 특징들이 잘 분리되어 있다(disentanged)고 말할 수 있는 것입니다.
하지만, 전통적인 방식에서는 일반적으로 latent vector z를 샘플링할 때 Gaussian distribution에서 샘플링했고, 이렇게 되면 factor들이 완전히 disentangle 되는 것을 보장할 수 없습니다. 즉, 각각의 factor들이 서로 얽히고설켜서 분리가 되지 않기 때문에 control 하기가 어려워집니다.

본 style GAN 논문에서는 z를 mapping 한 결과인 w vector를 쓰는 것이 disentanglement 측면에서 큰 이점이 있다고 설명합니다.
Figure 6의 (a)를 학습 데이터셋 분포이며 다음과 같은 가정을 하겠습니다.
- 세로축은 성별을 나타내는 feature, 가로축은 머리 길이 feature에 대한 축
- 빨간 부분: 머리 긴 여성
- 파란 부분: 머리 짧은 여성
- 노란 부분: 머리 짧은 남성
- 머리 긴 남성 데이터가 없는 상태
이러한 데이터 셋으로 학습을 진행했을 때 Gaussian distribution에서 하나의 latent vector를 샘플링해서 이미지를 만들면 어떻게든 Gaussian distribution에 맞게 latent space를 매칭시킬 것입니다. 따라서, 필연적으로 feature들이 더욱더 많이 entangle 될 수밖에 없습니다.
(b)에서 빨간색은 머리가 긴 여자였고요, 여기 노란색은 머리가 짧은 남자인데, 이 두 포인트에 대해서 interpolation을 수행했을 때 중간 위치에서는 급격하게 이미지의 시멘틱한 정보가 많이 바뀔 수 있다는 것입니다.
Gaussian 분포에서 샘플링한 데이터를 그대로 network에 넣는 경우에는 각각의 특징들이 서로 얽히고 entangle 된 문제가 발생할 수 있다는 거죠.
하지만 w space로 mapping 한 뒤에 intermediate latent space에서 interpolation을 수행하는 경우 w에서 샘플링을 수행한 데이터가 고정된 distribution에 따라서 샘플링할 것을 support 할 필요가 없기 때문에 즉, 굳이 Gaussian 분포를 따를 필요가 없기 때문에 상대적으로 각각의 feature들이 잘 분리될 수 있는 형태로 학습될 가능성이 높습니다. 이에 따라, 학습 시 상대적으로 덜 급격하게 이미지가 바뀌게 됩니다.
이때 단순히 경험적으로 성능이 좋다고 말하는 것이 아니라 w vector를 사용할 때 정말 disentanglement의 이점을 얻을 수 있는가를 분석하기 위해서 새롭게 두 가지 평가 지표를 제안하였습니다.
4.1. Perceptual path length
그중 첫 번째는 perceptual path length로 두 개의 vector를 interpolation 할 때 급격하게 변화가 일어나지 않고 smooth 하게 데이터가 그럴싸한 상태를 유지하면서 바뀌는 걸 측정합니다.
즉 얼마나 drastic 하게 이미지가 바뀌는지를 측정해서 그렇게 바뀌는 정도가 낮을수록 더 성능이 좋다고 판단합니다.
상대적으로 latent space가 덜 휘어 있다면 A랑 B를 interpolation 할 때 더욱더 부드럽게 바뀌는 것과 같은 효과를 낼 수 있을 것입니다.
일반적으로 이미지를 인간의 시각으로 얼마나 그럴듯하게 보이는지 평가하기 위해 VGG 네트워크의 feature 값을 분석하는 방법을 많이 사용하는데, 본 논문에서도 사전 학습된 VGG 분류 네트워크를 이용하여 perceptual loss를 계산합니다.
공식은 다음과 같습니다.

일반적으로 우리가 z1과 z2에 대해서 interpolation을 수행한다고 하면 얼마만큼의 비율로 interpolation을 수행할지 정확히 중간에 어떤 지점을 뽑을지(= 두 이미지 사이에서 얼마나 섞을지)를 이 t라는 상수로 명시할 수 있습니다.
e는 굉장히 작은 상수로 특정 포인트에서 굉장히 가까운 다른 포인트를 또 뽑을 수 있도록 합니다.
그러면 두 z1과 z2를 interpolation 한다고 할 때 특정 interpolation 지점과 그 바로 옆에 있는 지점 사이에서 샘플링된 결과에서의 perceptual 거리를 계산해서 두 이미지가 얼마나 많이 feature 상에서의 변화가 있었는지를 분석할 수 있습니다.
이러한 거리값이 작다는 것은 우리가 interpolation을 수행할 때 이미지가 갑자기 막 이상한 형태로 바뀔 가능성이 낮다는 것을 의미합니다.
이때 두 가지 측면에서 모두 비교하는데요. 먼저 z vector를 이용해서 interpolation을 수행할 때, 그리고 w vector에서의 interpolation을 수행할 때 각각을 비교합니다. 후자의 공식은 다음과 같습니다.
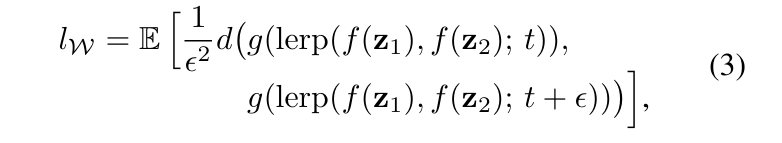
참고로 latent vector인 z는 Gaussian distribution에서 샘플링하기 때문에 interpolation을 진행할 때는 spherical interpolation을 사용합니다.
반면에 w vector끼리 interpolation을 수행할 때는 그냥 단순하게 선형 보간을 이용했다고 말하고 있습니다.
perceptual path length를 구해 본 결과 w space에서 interpolation을 수행할 때 훨씬 좋은 성능이 나왔으며 이는 다시 말해 interpolation을 수행할 때 급격한 변화가 적었다는 것을 의미합니다.
table 3번에서 그 결과를 확인할 수 있습니다.
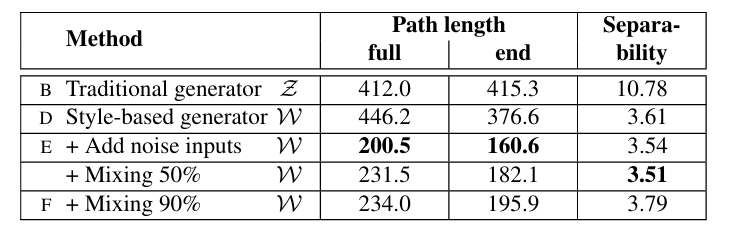
표를 보면 학습을 수행할 때 style mixing을 사용하지 않을 때가 더 path length가 작은 걸 확인할 수 있습니다.
mixing이 일반적인 interpolation과는 다르게 각각의 layer에 들어가는 style 정보들이 서로 uncorrelated 될 수 있도록 만드는 것이 목표라고 언급한 바가 있습니다.
그런 측면에서 고려해 보았을 때 오히려 perceptual path length 측면에서는 어느 정도 latent space w에 대해서 왜곡을 발생시킬 수 있기 때문에 이러한 결과가 나온다고 이해할 수 있습니다.
4.2. Linear separability
linear separability는 말 그대로 선형적으로 얼마나 잘 분리될 수 있는가를 의미합니다.
이를 위해서 간단한 선형 분류기를 학습한 뒤에 그 선형 분류기에 따라서 서로 다른 특징이 얼마나 잘 구분되는가를 평가하였습니다.
즉 선형 분류기를 학습한 뒤에 entropy를 계산해서 latent vector가 얼마나 선형적인 sub-space에 존재하는지를 확인할 수 있는 거죠.
CelebA-HQ는 총 40개의 binary attribute를 가지는 데이터 셋입니다. 이에 따라 각각의 이미지마다 남성인지 여성인지, 웃고 있는지 웃고 있지 않은지 이러한 binary 정보를 40개씩 가지고 있습니다. 그래서 각각의 attribute에 대해서 별도의 선형 분류기를 학습합니다.
예를 들어, 어떠한 이미지가 들어왔을 때 그 이미지가 남자인지 여자인지를 구분하는 하나의 선형 분류기가 학습되었다고 가정해 보겠습니다.
이후에 generator를 이용해서 여러 개 랜덤 한 이미지를 만든 뒤에 아까 학습해 두었던 그 분류 모델에 넣어서 남자인지 여자인지 각각 구해낼 수 있도록 하는 것입니다. 여기에서 confidence가 낮은 값들은 제거해서 더욱더 각각의 특징을 많이 가지고 있는 이미지만 남길 수 있도록 합니다.
정리하자면 CelebA-HQ 데이터 셋을 이용해서 먼저 간단하게 보조 network를 학습한 뒤에 이러한 보조 network를 이용해서 생성자에서 20만 개의 이미지를 생성한 뒤에 그 20만 개의 이미지를 이러한 보조 network에 넣어서 그중에서 신뢰도가 높은 10만 개만 추려서 얘네들을 새로운 데이터 셋으로 활용하겠다는 겁니다.
이렇게 해 주는 이유는 우리는 latent space 상에서의 separability를 측정하고 싶은 것이기 때문에 이런 latent space를 가로지르는 선형 분류기를 학습할 필요가 있기 때문이죠. 그래서 여기 나와 있듯이 latent space에 포인트를 분류할 수 있는 하나의 선형 분류기를 학습하고요.
이때 style GAN에 대해서는 w를 쓰고 전통적인 생성자에서는 z를 썼습니다. 이렇게 학습을 하고 나면 각각의 latent vector가 선형 분류기로부터 얼마나 떨어져 있는지를 구할 수 있고 또한 다른 방법으로는 conditional entropy 값을 구할 수 있습니다.
여기서 conditional entropy 값은 하나의 입력 vector인 x가 주어졌을 때, 그때의 true class에 대한 entropy가 얼마나 높은 지를 측정할 수 있는 겁니다. 이는 다른 말로 하면 x가 특정 true class로 분류되기 위해서 얼마나 feature가 부족한지에 대한 내용을 담습니다. entropy 값이 높을수록 그 이미지를 해당 true class에 대한 feature를 잘 담지 못하고 있다는 거죠.
여러 개의 이미지를 가지고 있을 때 각각 entropy를 계산해서 이런 entropy가 높다는 것은 선형 분류기로 latent vector를 잘 분리할 수 없다는 말이 되고 다른 말로 하면 linear 하게 분포되어 있지 않다는 의미입니다.
결과적으로 이러한 entropy가 낮을수록 더 선형적으로 분류가 잘 된다고 이해할 수 있습니다.

table 4를 확인해 보시면 알 수 있듯이 우리가 전통적인 GAN을 쓰든 혹은 style based GAN을 쓰든 항상 w vector를 사용할 때가 훨씬 separability가 높은 걸 확인할 수 있습니다.
즉 mapping layer를 사용해서 mapping을 거친 이후에 w space에서 interpolation을 할 때가 성능이 훨씬 좋은 성능을 낼 수 있다는 걸 보여주는 겁니다.
숫자는 mapping network의 깊이를 의미합니다. 기본적으로 mapping network에 layer가 많으면 많을수록 조금 더 좋은 성능이 나오는 걸 확인할 수 있습니다.
이러한 결과는 우리가 전통적인 generator의 architecture를 사용하든 style based generator를 사용하든, 별도의 mapping network를 사용할 때 훨씬 linear 한 latent의 sub-space를 갖도록 만들 수 있다는 걸 알 수 있습니다.
5. Conclusion
결과적으로 본 논문에서는 styleGAN을 제안하고 styleGAN은 전통적인 GAN보다 훨씬 좋은 성능을 내는 걸 확인할 수 있습니다. 전통적인 GAN의 style based architecture보다 모든 면에서 훨씬 더 우수한 편이라고 표현할 수 있으며, 다양한 metric을 통해서 입증합니다.
또한 본 논문의 큰 장점이라고 할 수 있는 각각의 high-level 특징들이 잘 분리되고, stochastic variation 또한 control이 가능하며, 실제로 latent space 상에서 적절히 각각의 vector들이 선형적으로 분리되는 것 또한 확인할 수 있었습니다.
추가적으로 본 논문에서 제안한 perceptual path length라는 metric 자체를 loss 함수로 구성해서 그 metric 자체를 줄이도록 학습 과정에서 사용할 수도 있을 것입니다.

+ Appendix
truncation trick
위에서 언급했듯이 논문에서는 안정적이고 quality 높은 이미지를 얻기 위해서 truncation trick을 사용했습니다.
low density 영역에서 샘플링을 진행하면 덜 그럴싸한 이미지가 나올 확률이 높아지기 때문에 평균 latent vector에 가까워질 수 있도록 해서, 이를 truncation을 진행해서 보다 그럴싸한 이미지를 만들어 낼 수 있다는 것입니다.

truncation parameter ψ 값을 0에 가깝게 만들수록 완전히 평균 이미지로 잘라내기가 수행되기 때문에 항상 동일한 평균적인 이미지가 나오고, 이 값이 1에 가까울수록 truncation 제약 조건이 사라지게 됩니다.
즉 truncation parameter ψ 값이 1에 가까울수록 truncation을 진행하지 않는 거고, 0에 가까울수록 truncation을 많이 진행하는 것 입니다.
C. Hyperparameters and training details
- Tesla V100 GPU 8장, 일주일 정도 학습 진행
- 원본 PGGAN 논문에서는 4x4 크기에서 출발, 본 논문에서는 8x8부터 출발해서 layer 늘림
- latent vector인 z와 w는 각각 512차원
D. Training convergence
D에서는 전통적인 방법과 본 논문의 style based GAN과 학습이 진행되는 과정에서 FID와 path length가 얼마나 차이가 나는지를 보여주고 있습니다. 참고로 두 설정 모두에서 R1 regularization이 사용되었습니다.
그래프를 보면 알 수 있듯이 훈련이 진행됨에 따라 FID 값은 천천히 감소했으며, 이는 더 많은 이미지를 훈련에 사용하기로 결정한 이유입니다(1200만 이미지에서 2500만 이미지로 증가).
이러한 양상은 FID가 증가함에 따라서 더욱 그럴싸한 이미지가 만들어질 수 있음에 따라서 linearly separable 한 특징은 상대적으로 특징들이 더욱 entangle 될 수 있다는 점을 보여주고 있는 것입니다.
하지만, path length는 해상도가 1024x1024로 완전히 올라간 후에도 천천히 증가했습니다. Path length는 생성된 이미지의 복잡성을 나타내는 지표이기 때문에 이는 FID가 개선될수록 이미지는 더 entangle 된다는 것을 의미합니다. 일종의 trade-off 관계에 있다고 할 수 있습니다.
따라서, 앞으로의 연구에서 이 복잡성이 피할 수 없는 것인지, 아니면 FID를 유지하면서 path length를 줄일 수 있는 방법이 있는지 알아보는 것이 흥미로운 주제가 될 것이라 언급합니다.

E. Other datasets
왼쪽에 보이는 그림은 LSUN bedroom 데이터셋, 오른쪽은 LSUN 자동차 데이터셋입니다.
본 논문 저자들은 FFHQ를 학습할 때와 마찬가지의 setup으로 두 데이터 셋에 대해서도 학습을 진행하였고, 그 결과 FFHQ를 이용해 학습을 진행했을 때와 유사한 속성들이 잘 드러났다고 말합니다.
예를 들어 bedroom 데이터셋의 경우 coarse style을 변경하게 되면 카메라의 구도와 같은 정보가 바뀌게 되고, middle style의 정보를 바꾸게 되면 특정 가구와 같은 정보가 바뀌며, fine style을 바꾸게 되면 색상 변화나 재질과 같은 부분이 많이 바뀌는 걸 확인할 수 있습니다.

Reference
https://www.youtube.com/watch?v=HXgfw3Z5zRo
'ML & DL > GAN' 카테고리의 다른 글
| StyleGAN2-ADA 학습 튜토리얼 (AHFQ-v2 Dataset 사용) (0) | 2024.10.27 |
|---|---|
| loss 값이 nan이 되는 이유 및 오류 해결(feat. StyleGAN) (0) | 2024.10.22 |
| CycleGAN 모델 파라미터 정리 (0) | 2024.07.31 |
| 쉽게 설명하는 CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 논문 리뷰 (5) | 2024.06.11 |
오늘은 StyleGAN이 등장한 논문
"A Style-Based Generator Architecture for Generative Adversarial Networks"을 리뷰해보려고 합니다.
이 글은 나동빈님의 https://www.youtube.com/watch?v=HXgfw3Z5zRo 리뷰 영상을 참고하여 작성하였습니다.
StyleGAN은 이미지 생성 네트워크 중에서 뛰어난 성능을 보이는 아키텍처를 제안합니다.
우선 StyleGAN을 등장시킨 Style-Based Generator Architecture for Generative Adversarial Networks의 주요 contribution은 다음과 같습니다.
- PGGAN을 기반으로 style transfer 분야의 아이디어를 활용해 고성능의 generator를 만들어냅니다. 본 연구는 generator architecture에 초점이 맞춰진 연구로 discriminator에는 변화를 주지 않았습니다.
- 스타일 정보의 분리를 가능하게 해서 서로 다른 특징들을 보다 쉽게 컨트롤할 수 있게 합니다.
- style끼리의 disentanglement를 측정하는새로운 metric을 도입합니다.
- perceptual path length
- linear separability
- 1024x1024 크기의 고해상도 사람 얼굴 dataset인 FFHQ를 배포하고 누구나 다운로드받아 학습을 진행할 수 있도록 했습니다.
그럼 본격적으로 논문 순서대로 StyleGAN에 대해서 리뷰해 보도록 하겠습니다.
1. Introduction
Introduction에서는 위에서 설명한 contribution에 대한 간단한 설명을 진행합니다.
<1> PGGAN + style transfer → 고성능의 generator 제안
원본 GAN 논문 이후, 특히 이미지 생성 분야에서 다양한 기술들이 제안되어 왔습니다.
그중 PGGAN 또는 ProGAN은 고해상도 이미지 생성에서 주목받았지만, GAN 내부의 동작 원리는 여전히 블랙박스처럼 느껴졌습니다. 이미지 생성 시 stochastic feature를 제어하는 방법이나 latent space에 대한 연구도 부족했습니다.
일반적으로 서로 다른 두 이미지 사이의 latent vectors에서 interpolation을 수행해 네트워크 성능을 평가했지만, 정량적인 평가가 어려웠습니다.
본 논문은 generator 설계를 개선하기 위해 style transfer 아이디어를 적용하여 StyleGAN을 개발했습니다. StyleGAN은 이미지의 해상도를 점차 키워가며 다양한 스타일을 적용해 이미지를 생성하는 방식입니다. 학습된 상수에서 시작해 여러 블록을 거치며 해상도가 커지고, 마지막에는 RGB 컬러로 변환해 결과 이미지를 만듭니다. 각 블록마다 스타일 정보를 입력받아 많은 스타일이 반영되며, stochastic variation도 제어 가능합니다.
주목할 점은, 이러한 기능들은 모두 generator를 수정하여 얻은 결과이며, discriminator나 loss function은 거의 수정하지 않았다는 것으로 본 논문의 핵심 기여입니다.
<2> 서로 다른 특징들을 보다 컨트롤
일반적으로 generator는 어떠한 랜덤한 latent code를 받아서 다양한 이미지를 만들 수 있는데, 보통은 uniform distribution이나 gaussian distribution에서 하나의 noise vector를 뽑아서 입력으로 넣는 방식을 사용합니다.
본 논문에서는 latent code를 한 번 intermediate latent space로 보내준 뒤, 그 space에서 generator의 input으로 들어갈 수 있도록 만듭니다.
그 이유는 다음과 같습니다.
기본적으로 입력 latent space가 트레이닝 데이터의 확률 밀도 함수를 따를 수밖에 없기 때문에, 단순하게 가우시안 분포에서 샘플링한 노이즈를 입력으로 넣게 되면 어느 정도 entanglement가 발생할 수 밖에 없습니다.
반면, intermediate space로 한 번 매핑한 뒤, 거기에서 실제 네트워크에 입력하게 되면 특정한 분포를 꼭 따라야 한다는 제약이 사라지기 때문에 disentanglement 측면에서 이점을 얻을 가능성이 높아진다는 것입니다.
<3> 새로운 metric을 도입해서 style끼리의 disentanglement 측정
본 논문에서는 perceptual path length와 separability 이 두 가지 metric을 제안했습니다.
이 metric은 각각의 특징들이 얼마나 선형적으로 잘 분리되면서 그리고 interpolation 과정에서 자연스러운 이미지를 만들 수 있는지에 대한 적절한 평가 지표로서 사용될 수 있습니다.
본 논문에서는 실제로 이러한 metric을 활용했을 때, 제안한 generator architecture는 훨씬 linear하게 동작하면서 representations이 서로 덜 얽혀서 특징들을 컨트롤하기 쉽게 만들었다고 주장합니다.
<4> 고해상도 사람 얼굴 dataset인 FFHQ를 배포
마지막으로 본 논문에서는 지금은 잘 알려진 고해상도 얼굴 dataset FFHQ를 배포해서 많은 사람들이 고해상도 이미지 데이터셋으로 학습을 진행할 수 있도록 했습니다.
2. Style-based generator
2장에서는 제안한 generator architecture를 설명하며, 기존의 어떤 방법과 어떤 방식이 다른지 설명하는 방식으로 논문을 전개합니다.
일반적으로 이전까지의 generator는 하나의 latent vector를 넣을 때, 말 그대로 latent vector에 따라서 다양한 이미지가 생성될 수 있도록 만들었습니다. 그러나 본 네트워크에서는 별도로 스타일 정보를 layer를 거칠 때마다 따로 넣어줍니다. 따라서, 처음부터 latent 코드로 시작하지 않고 하나의 학습된 상수(const 4x4x512)를 그 자체로서 generator에 입력으로 넣어줄 수 있도록 하고, 그러한 학습된 상수가 convolution layer를 거치는 과정에서 스타일에 대한 정보를 입력받아 다양한 이미지를 생성할 수 있도록 구성되어 있습니다.
즉, 일반적인 네트워크와 다른 점은 generator의 입력으로 들어가는 것이 일반적인 latent vector가 아니라 학습된 하나의 상수 이미지로서 입력된다는 점입니다.
또한 중요한 특징 중 하나는 별도의 Gaussian distribution이나 uniform distribution에서 noise를 샘플링하여 바로 넣는 것이 아니라, 별도의 비선형 매핑을 통해 W vector로 바꾸고, 이 W vector가 실제 입력으로 들어갈 수 있도록 만드는 것입니다.
Figure 1을 확인해 보시면, 왼쪽에 있는 architecture는 일반적인 general architecture로 논문의 baseline architecture인 PGGAN의 architecture입니다. PGGAN에서는 특정한 분포에서 하나의 latent vector인 Z를 바로 샘플링을 해서 정규화를 거친 뒤에 입력으로 들어갑니다.
그러나 본 논문에서 제안한 StyleGAN은 이러한 latent vector인 Z를 뽑은 뒤에 하나의 매핑 네트워크를 거쳐서 W vector로 바꾸고, 이 W vector가 입력으로 들어갈 수 있는 형태로 구성됩니다.
W vector를 만든 뒤에는 W vector를 각각의 block마다 두 번씩 별도의 affine transtform을 거쳐 입력될 수 있도록 만듭니다. 그 부분이 'A' 부분입니다.
systhesis network g는 4x4 짜리 너비와 높이를 가진 텐서로부터 출발해서, 각 block을 거칠수록 너비와 높이는 두 배로 증가하게 되어 마지막 결과 이미지가 1024x1024가 되고 block은 총 9개 들어가게 됩니다.
그런 9개의 block마다 두 번씩 스타일 벡터가 들어가기 때문에 결과적으로 generator에 들어가는 스타일 벡터는 18x512차원짜리 하나의 행렬이 됩니다. 즉 block이 9개고 2번씩 들어가니까 스타일 벡터가 총 18개로 분리되어 들어간다고 이해할 수 있습니다.
또한, 본 논문에서는 한 명의 사람 이미지에서 조금씩 확률적으로 바뀔 수 있는 정보인 주근깨나 머릿결, 피부 컨디션과 같은 stochastic variation을 처리할 수 있도록 하기 위해 별도의 noise vector 또한 입력으로 받습니다. Figure (b)의 'B' 부분으로 마찬가지로 각 block마다 2개씩 들어가는 형태가 유지됩니다.
여기서 A의 경우 하나의 512차원짜리 W 벡터가 있을 때 거기에서부터 스타일 정보를 가져올 수 있도록 만드는데요, 이때 style transfer network는 일반적으로 AdaIN이라는 하나의 normalization layer를 사용하여 하나의 feature에 대한 정보를 입력받은 style의 statistics을 이용해서 하나의 feature에 대한 statistics을 바꿀 수 있도록 만듭니다.
정확히는 scaling과 bias를 적용함으로써 convolution 연산을 통해 얻은 feature output의 통계적인 정보를 바꾸는 방식으로 style을 입힐 수 있습니다.
noise에 대한 정보는 항상 convolution 연산 이후에 들어가고, 그렇게 얻어진 feature map의 각 channel에 대해서 통계적인 정보를 변경할 수 있도록 style 정보를 받아서 AdaIN layer를 거쳐 해당 style을 적용할 수 있도록 만듭니다. 이러한 과정을 반복해서 그럴듯하면서도 다양한 결과 이미지를 얻을 수 있는 것입니다.
Figure 1 과정을 정리하면 먼저 input을 latent vector를 w space의 한 vector로 바꿔주고 별도의 affine layer를 거쳐서 style 정보를 얻은 뒤에 AdaIN layer를 거쳐서 각각의 convolution layer를 거친 결과에 대해서 style 정보를 적용할 수 있도록 만듭니다.
B 같은 경우는 noise가 적용될 수 있도록 하기 위한 affine transformation이고요. 또한 mapping network는 8개의 layer로 구성되어 512차원의 input을 다른 512차원의 W ouput으로 만들어주는 network입니다.
또한 generator는 18개의 layer로 구성되며 총 9개의 block이 존재하므로 각 block마다 2개의 convolution layer로 구성된다고 이해하시면 되겠고요, 4x4에서 1024x1024까지 저해상도에서 고해상도로 점차 해상도를 늘려가는 방식으로 이미지를 만든다고 보시면 되겠습니다. 한 번에 저해상도에서 고해상도 이미지를 만들기는 어렵기 때문에 일반적으로 여러 개의 block을 거쳐서 단계적으로 이미지 해상도를 증가시키는 방법을 사용하는 것입니다.
마지막에는 channel 사이즈가 얼마가 됐든 간에 결과 이미지를 만들 수 있어야 되기 때문에 RGB color를 가질 수 있는 3차원의 tensor가 될 수 있도록 만듭니다. 흔히 이를 to RGB layer라고 부르며 이러한 layer는 이전 논문의 PGGAN 논문에서도 사용되었던 technique이고 본 논문 또한 이러한 방식을 그대로 쓴다고 말하고 있습니다.
그래서 전통적인 생성자에 비교했을 때 parameter 수는 그렇게까지 많이 증가하지 않으면서 성능은 훨씬 개선될 수 있기 때문에 효과적인 architecture를 가질 수 있습니다.
위 식이 Adaptive Instance Normalization 즉 AdaIN에 대한 식입니다.
AdaIN layer는 일반적으로 feed-forward 방식의 style transfer network에서 효과적으로 사용되는 정교한 layer이며, 원래는 한 장의 content 이미지가 있을 때 다른 style 이미지로부터 그 style 정보를 받아와서 AdaIN을 거쳐서 content 이미지의 feature statistics를 변경함으로써 style transfer를 수행할 수 있도록 하는 방법입니다.
여기서 x에 대해서 평균값을 빼고 standard deviation으로 나누어 주는 연산은 일반적인 정규화이고 추가적으로 scaling과 bias를 적용함으로써 feature space에서의 statistics를 변경할 수 있습니다.
아까 하나의 고정된 tensor에서부터 출발해서 layer를 거쳐가면서 결과 이미지가 된다고 했는데 그 고정된 tensor에서부터 출발한 AdaIN layer를 거치기 전 input 값이 x이고, AdaIN layer를 거쳐서 매번 style 정보가 바뀌는 내용이 바로 이 y에 의해서 control 되는 것입니다.
추가로 Instance Normalization과 Batch Normalization의 차이점이라고 한다면 Batch Normalization에서는 channel당 하나의 batch에 포함되어 있는 모든 이미지를 걸쳐서 channel 당 정규화를 수행합니다. 반면, Instance Normalization에서는 한 이미지에 대해서 각각 channel당 정규화를 수행하는 것입니다.
Instance Normalization이 훨씬 style transfer 측면에서 잘 동작한다는 것이 밝혀졌기 때문에 style transfer에 잘 활용되고 있는 것입니다.
따라서, xi는 각각의 channel당 feature map이며, 이들이 전부 개별적으로 정규화된 이후에 scaling과 bias를 적용해서 style transfer를 수행하는 방식이 적용되는 것입니다.
2.1. Quality of generated images
Table 1은 baseline architecture와 비교했을 때 본 논문에서 제안한 메소드를 적용해서 얼마나 FID 성능이 좋아지고 있는지를 보여줍니다. 여기서 FID는 생성자의 quality를 측정하기 위한 전통적인 방법입니다.
여기에 baseline architecture인 PGGAN부터 조금씩 메소드가 추가되고 있는 것이기 때문에 F가 본 논문에서 제안한 모든 기법들을 다 적용한 결과입니다.
Dataset
- CelebA-HQ: 기존에 많이 사용되었던 잘 알려진 얼굴 데이터셋 CelebA 의 고해상도 버전
- FFHQ: 본 논문에서 새롭게 배포한 데이터셋
Method
- A: baseline architecture = PGGAN
- B: 튜닝
- upsampling과 downsampling을 수행할 때 interpolation 메소드를 바꿈
- training을 더 길게
- 하이퍼 파라미터 튜닝
- C: mapping network 추가, style transfer 아이디어를 적용(= AdaIN연산 추가)
- D: 전통적인 latent vector를 입력으로 받지 않고 4x4x512 차원의 학습된 상수 tensor로부터 출발하도록 만든 것 = 고정된 상수로부터 출발하고 결과 이미지를 만들어내기까지 style을 입혀 나가는 방식 사용
- E: noise input 적용
- F: mixing regularization 사용
그래서 styleGAN을 이용해서 만들어낸 다양한 이미지는 Figure 2에 나와 있습니다. 별도로 잘 나온 것만을 선별하지 않고 style GAN 자체가 이 정도의 quality를 항상 낼 수 있다고 말하고 있습니다.
물론 일반적으로 높은 quality의 이미지를 만들기 위해서는 truncation trick을 사용되는데요. 여기에서도 마찬가지로 truncation trick을 활용해서 이미지를 뽑은 것이라고 밝히고 있습니다.
truncation trick
truncation trick이란,
하나의 GAN 모델을 학습 완료한 뒤에 샘플링을 수행할 때 그럴싸한 이미지가 잘 나올 수 있도록 더욱 평균에 가까운 이미지가 나올 수 있게 이 latent vector에 truncation을 적용한 것입니다.
학습을 완료한 후 샘플링을 수행할 때 probability density가 높은 부분에서 샘플링을 수행하면 당연히 더 그럴싸한 이미지가 나올 수 있겠지만, 모든 요소에 대해서 현실적으로 샘플링을 수행할 때는 그럴싸하지 않은 이미지 또한 만들어질 수 있기 때문에 가능하면 density가 높은 이미지에서부터 샘플링을 수행할 수 있도록 하기 위해 하나의 latent vector가 latent vector space에서 중간에 가까운 값이 될 수 있도록 잘라내기(truncation)를 수행해서 결과를 얻도록 만드는 것입니다.
3. Properties of the style-based generator
3절에서는 본격적으로 styleGAN에 대한 속성을 분석해서 명시합니다.
styleGAN architecture를 사용하면 style의 특정 subset을 바꾸는 것은 이미지의 특정한 양상을 바꾸는 효과를 낼 수 있는데, 이러한 특징을 다른 말로 localization라고 합니다.
즉 layer의 특정 부분에 대한 style을 바꾸는 것은 특정한 양상을 바꾸는 형태로 동작할 수 있습니다.
기본적으로 AdaIN 연산은 각각의 channel에 대해서 정규화를 수행하기 때문에 feature map마다 정규화를 수행한다고 할 수 있고, 매번 convolution 연산 이후에 normalization을 수행하기 때문에 각각의 style이 서로 다른 특징을 나타내도록 분리될 수 있습니다.
다시 말해 각각의 style은 하나의 convolution에 대해서 적용되고 다음 AdaIN 연산에 의해서 덮어쓰기가 수행될 수 있다는 점이 이러한 특징을 분리하는 데 더욱 기여하는 요소가 될 수 있다는 것입니다.
3.1. Style mixing
본 논문에서는 각각의 style이 더욱 localize 되어서 다른 layer에는 관여하지 않도록 만들기 위해서 즉 더욱 잘 localize시키기 위해서 style mixing이라는 technique을 제안합니다.
Table 1 F에서 추가된 method, mixing regularization과 같은 내용입니다.
방법은 간단합니다.
두 개의 latent vector가 있을 때, 학습 진행 시 단순히 한 개의 latent vector만 뽑아서 이미지를 만드는 것이 아니라 두 개의 latent vector를 서로 섞어서 이미지를 만들 수 있도록 하는 것입니다.
섞는다는 말은 crossover point를 사용한다는 것입니다.
예를 들어서 앞쪽 layer에서는 w1을, 뒤쪽 layer에서는 w2를 쓰는 방식을 사용할 수 있습니다.
여기에서 의도하는 내용은 각각 들어가는 style들이 서로 다른 style과 상관관계를 가지지 않도록 하는 것이므로
여기에서 말하는 mixing은 두 vector 간 interpolation하는 것이 아니라, 특정 앞쪽 layer까지는 vector1을 쓰고, 뒤쪽 layer부터는 vector2를 쓰는 방식을 의미합니다.
그렇게 함으로써 인접한 layer가 이러한 style끼리 서로 상관관계를 갖지 않도록 유도할 수 있습니다.
다시 말해 style mixing은 인접한 style끼리의 correlation을 줄이고 더욱 지역화될 수 있도록 만들기 위한 technique입니다. 그래서 crossover point를 설정하고, w1과 w2 vector가 교차되어 적용된 하나의 vector를 실제 학습에 사용할 수 있도록 만들어서 각각의 layer에 따른 style들이 서로 correlation이 사라질 수 있도록 유도했습니다.
Figure 3가 실제 styleGAN을 이용해서 여러 개의 이미지 사이에서 style mixing을 수행한 결과입니다.
즉 여기에서는 interpolation이라고 하기보다는 두 개의 latent vector가 있을 때 각각의 layer에 따라서 어떤 layer에서는 source B를 쓰고, 어떤 layer에서는 source A를 쓴 결과입니다.
실제로 style mixing을 수행한 결과들은 source B의 style 중에서 특정 subset과 source A의 style 중에서 그 나머지 subset을 합친 것이라는 의미입니다.
layer마다 서로 다른 latent vector로부터의 style을 사용했다라고 이해하시면 되겠습니다.
자, 그래서 source A의 특정한 정보를 source B에서부터 가져와서 style mixing을 수행한 건데요.
왼쪽에 나와있는 course, middle, fine style은 다음과 같습니다.
- Coarse Style
- 전반적인 sementic feature들을 바꿀 수 있는 style (포즈, 얼굴형, 안경 여부 등)
- 네트워크의 앞쪽 레이어에 적용되기 때문에 최종 이미지의 큰 시멘틱 요소에 큰 영향을 미친다.
- Middle Style
- 중간 수준의 특징들(헤어스타일, 눈을 뜨거나 감은 상태 등)
- 중간 스타일 정보는 5번째부터 8번째 W 벡터에 적용된다.
- Fine Style
- 작은 세부 특징들(색상, 미세한 구조 차이 등)
- 세밀한 스타일 정보는 네트워크의 뒤쪽 레이어에 적용된다. 뒤쪽 레이어에서는 영향을 미칠 수 있는 패치의 크기가 작기 때문에 세밀한 정보 위주로 바뀐다.
Table 2는 FID 측면에서 mixing regularization의 영향을 분석한 결과입니다.
mixing regularization을 많이 사용할수록 style mixing을 수행했을 때에도 그럴싸한 결과가 잘 나올 수 있다는 걸 보여줍니다.
3.2. Stochastic variation
이어서 stochastic variation에 대해서 분석합니다.
Figure 4는 하나의 동일한 style vector에 대해서 noise vector만 바꾼 결과들을 보여줍니다. style은 유지한 상태로 noise만 바꾸었을 때 확률적인 정보들이 조금씩 바뀌는 걸 확인할 수 있습니다.
여러 번 noise를 바꾸어서 standard deviation을 분석한 결과 그림처럼 특히 머리카락과 같은 정보가 많이 바뀌는 걸 확인할 수 있었다고 합니다.
참고로 TensorFlow나 PyTorch로 구현할 때 style 정보가 동일하게 들어오더라도 매번 noise vector는 바뀔 수 있도록 설정이 되어 있기 때문에 구현 상 style을 유지하면서 단순하게 foward만 하더라도 매번 조금씩은 다른 이미지가 만들어지는 것이 디폴트입니다.
Figure 5는 generator의 여러 레이어에서 noise input이 미치는 영향을 설명합니다.
- (a): 원래 style
- (b): noise 적용하지 않음 → 특히 머리카락과 같은 부분에서 디테일이 많이 떨어짐
- (c): fine layer에 대해서만 noise 적용 → 머리카락의 컬링과 같은 큰 스케일적인 부분에 영향
- (d): coarse layer에 대해서만 noise를 적용 → 세밀한 머리카랑 컬링, 여러 디테일적인 부분에 영향
여기에서 이러한 noise는 오직 확률적인 양상에 대해서만 영향을 미치고 전반적인 구성 및 정체성 등의 high-level 측면에는 영향을 미치지 않는다는 것을 볼 수 있습니다.
다시 말해, 이미지에 대한 high-level feature aspects는 style을 이용해서 control 할 수 있고 noise로는 control 하기 어렵다는 걸 보이고 있습니다.
또한, noise는 network의 각 layer에서 사용 가능하며, generator는 새로운 콘텐츠 도입을 위해 이를 활용하여 stochastic variation을 생성합니다.
3.3. Separation of global effects from stochasticity
그래서 본 논문에서는 w vector가 실제로 포즈를 바꾸거나 얼굴에 해당하는 정체성을 바꾸는 등 더욱더 글로벌한 효과를 가지고 있고, noise는 상대적으로 더욱 확률적인 다양성 측면에서 영향을 미칠 수 있다고 언급합니다.
4. Disentanglement studies
이어서 본 논문에서는 style GAN network의 disentanglement 측면에서도 연구를 진행했습니다.
disentanglement는 latent space를 linear sub-space를 갖도록 하는 것을 말하는 것이고, linear 하기 때문에 latent space에 존재하는 두 개의 vector를 뽑은 후, 두 vector 사이에 interpolation을 수행했을 때 훨씬 그럴싸하게 우리가 의도했던 특정한 feature만 바뀌는 방식으로 새로운 이미지를 얻을 확률이 높다는 것을 의미합니다.
특정한 factor를 바꿔서 개별적인 control이 가능하다면 여러 개의 특징들이 잘 분리되어 있다(disentanged)고 말할 수 있는 것입니다.
하지만, 전통적인 방식에서는 일반적으로 latent vector z를 샘플링할 때 Gaussian distribution에서 샘플링했고, 이렇게 되면 factor들이 완전히 disentangle 되는 것을 보장할 수 없습니다. 즉, 각각의 factor들이 서로 얽히고설켜서 분리가 되지 않기 때문에 control 하기가 어려워집니다.
본 style GAN 논문에서는 z를 mapping 한 결과인 w vector를 쓰는 것이 disentanglement 측면에서 큰 이점이 있다고 설명합니다.
Figure 6의 (a)를 학습 데이터셋 분포이며 다음과 같은 가정을 하겠습니다.
- 세로축은 성별을 나타내는 feature, 가로축은 머리 길이 feature에 대한 축
- 빨간 부분: 머리 긴 여성
- 파란 부분: 머리 짧은 여성
- 노란 부분: 머리 짧은 남성
- 머리 긴 남성 데이터가 없는 상태
이러한 데이터 셋으로 학습을 진행했을 때 Gaussian distribution에서 하나의 latent vector를 샘플링해서 이미지를 만들면 어떻게든 Gaussian distribution에 맞게 latent space를 매칭시킬 것입니다. 따라서, 필연적으로 feature들이 더욱더 많이 entangle 될 수밖에 없습니다.
(b)에서 빨간색은 머리가 긴 여자였고요, 여기 노란색은 머리가 짧은 남자인데, 이 두 포인트에 대해서 interpolation을 수행했을 때 중간 위치에서는 급격하게 이미지의 시멘틱한 정보가 많이 바뀔 수 있다는 것입니다.
Gaussian 분포에서 샘플링한 데이터를 그대로 network에 넣는 경우에는 각각의 특징들이 서로 얽히고 entangle 된 문제가 발생할 수 있다는 거죠.
하지만 w space로 mapping 한 뒤에 intermediate latent space에서 interpolation을 수행하는 경우 w에서 샘플링을 수행한 데이터가 고정된 distribution에 따라서 샘플링할 것을 support 할 필요가 없기 때문에 즉, 굳이 Gaussian 분포를 따를 필요가 없기 때문에 상대적으로 각각의 feature들이 잘 분리될 수 있는 형태로 학습될 가능성이 높습니다. 이에 따라, 학습 시 상대적으로 덜 급격하게 이미지가 바뀌게 됩니다.
이때 단순히 경험적으로 성능이 좋다고 말하는 것이 아니라 w vector를 사용할 때 정말 disentanglement의 이점을 얻을 수 있는가를 분석하기 위해서 새롭게 두 가지 평가 지표를 제안하였습니다.
4.1. Perceptual path length
그중 첫 번째는 perceptual path length로 두 개의 vector를 interpolation 할 때 급격하게 변화가 일어나지 않고 smooth 하게 데이터가 그럴싸한 상태를 유지하면서 바뀌는 걸 측정합니다.
즉 얼마나 drastic 하게 이미지가 바뀌는지를 측정해서 그렇게 바뀌는 정도가 낮을수록 더 성능이 좋다고 판단합니다.
상대적으로 latent space가 덜 휘어 있다면 A랑 B를 interpolation 할 때 더욱더 부드럽게 바뀌는 것과 같은 효과를 낼 수 있을 것입니다.
일반적으로 이미지를 인간의 시각으로 얼마나 그럴듯하게 보이는지 평가하기 위해 VGG 네트워크의 feature 값을 분석하는 방법을 많이 사용하는데, 본 논문에서도 사전 학습된 VGG 분류 네트워크를 이용하여 perceptual loss를 계산합니다.
공식은 다음과 같습니다.
일반적으로 우리가 z1과 z2에 대해서 interpolation을 수행한다고 하면 얼마만큼의 비율로 interpolation을 수행할지 정확히 중간에 어떤 지점을 뽑을지(= 두 이미지 사이에서 얼마나 섞을지)를 이 t라는 상수로 명시할 수 있습니다.
e는 굉장히 작은 상수로 특정 포인트에서 굉장히 가까운 다른 포인트를 또 뽑을 수 있도록 합니다.
그러면 두 z1과 z2를 interpolation 한다고 할 때 특정 interpolation 지점과 그 바로 옆에 있는 지점 사이에서 샘플링된 결과에서의 perceptual 거리를 계산해서 두 이미지가 얼마나 많이 feature 상에서의 변화가 있었는지를 분석할 수 있습니다.
이러한 거리값이 작다는 것은 우리가 interpolation을 수행할 때 이미지가 갑자기 막 이상한 형태로 바뀔 가능성이 낮다는 것을 의미합니다.
이때 두 가지 측면에서 모두 비교하는데요. 먼저 z vector를 이용해서 interpolation을 수행할 때, 그리고 w vector에서의 interpolation을 수행할 때 각각을 비교합니다. 후자의 공식은 다음과 같습니다.
참고로 latent vector인 z는 Gaussian distribution에서 샘플링하기 때문에 interpolation을 진행할 때는 spherical interpolation을 사용합니다.
반면에 w vector끼리 interpolation을 수행할 때는 그냥 단순하게 선형 보간을 이용했다고 말하고 있습니다.
perceptual path length를 구해 본 결과 w space에서 interpolation을 수행할 때 훨씬 좋은 성능이 나왔으며 이는 다시 말해 interpolation을 수행할 때 급격한 변화가 적었다는 것을 의미합니다.
table 3번에서 그 결과를 확인할 수 있습니다.
표를 보면 학습을 수행할 때 style mixing을 사용하지 않을 때가 더 path length가 작은 걸 확인할 수 있습니다.
mixing이 일반적인 interpolation과는 다르게 각각의 layer에 들어가는 style 정보들이 서로 uncorrelated 될 수 있도록 만드는 것이 목표라고 언급한 바가 있습니다.
그런 측면에서 고려해 보았을 때 오히려 perceptual path length 측면에서는 어느 정도 latent space w에 대해서 왜곡을 발생시킬 수 있기 때문에 이러한 결과가 나온다고 이해할 수 있습니다.
4.2. Linear separability
linear separability는 말 그대로 선형적으로 얼마나 잘 분리될 수 있는가를 의미합니다.
이를 위해서 간단한 선형 분류기를 학습한 뒤에 그 선형 분류기에 따라서 서로 다른 특징이 얼마나 잘 구분되는가를 평가하였습니다.
즉 선형 분류기를 학습한 뒤에 entropy를 계산해서 latent vector가 얼마나 선형적인 sub-space에 존재하는지를 확인할 수 있는 거죠.
CelebA-HQ는 총 40개의 binary attribute를 가지는 데이터 셋입니다. 이에 따라 각각의 이미지마다 남성인지 여성인지, 웃고 있는지 웃고 있지 않은지 이러한 binary 정보를 40개씩 가지고 있습니다. 그래서 각각의 attribute에 대해서 별도의 선형 분류기를 학습합니다.
예를 들어, 어떠한 이미지가 들어왔을 때 그 이미지가 남자인지 여자인지를 구분하는 하나의 선형 분류기가 학습되었다고 가정해 보겠습니다.
이후에 generator를 이용해서 여러 개 랜덤 한 이미지를 만든 뒤에 아까 학습해 두었던 그 분류 모델에 넣어서 남자인지 여자인지 각각 구해낼 수 있도록 하는 것입니다. 여기에서 confidence가 낮은 값들은 제거해서 더욱더 각각의 특징을 많이 가지고 있는 이미지만 남길 수 있도록 합니다.
정리하자면 CelebA-HQ 데이터 셋을 이용해서 먼저 간단하게 보조 network를 학습한 뒤에 이러한 보조 network를 이용해서 생성자에서 20만 개의 이미지를 생성한 뒤에 그 20만 개의 이미지를 이러한 보조 network에 넣어서 그중에서 신뢰도가 높은 10만 개만 추려서 얘네들을 새로운 데이터 셋으로 활용하겠다는 겁니다.
이렇게 해 주는 이유는 우리는 latent space 상에서의 separability를 측정하고 싶은 것이기 때문에 이런 latent space를 가로지르는 선형 분류기를 학습할 필요가 있기 때문이죠. 그래서 여기 나와 있듯이 latent space에 포인트를 분류할 수 있는 하나의 선형 분류기를 학습하고요.
이때 style GAN에 대해서는 w를 쓰고 전통적인 생성자에서는 z를 썼습니다. 이렇게 학습을 하고 나면 각각의 latent vector가 선형 분류기로부터 얼마나 떨어져 있는지를 구할 수 있고 또한 다른 방법으로는 conditional entropy 값을 구할 수 있습니다.
여기서 conditional entropy 값은 하나의 입력 vector인 x가 주어졌을 때, 그때의 true class에 대한 entropy가 얼마나 높은 지를 측정할 수 있는 겁니다. 이는 다른 말로 하면 x가 특정 true class로 분류되기 위해서 얼마나 feature가 부족한지에 대한 내용을 담습니다. entropy 값이 높을수록 그 이미지를 해당 true class에 대한 feature를 잘 담지 못하고 있다는 거죠.
여러 개의 이미지를 가지고 있을 때 각각 entropy를 계산해서 이런 entropy가 높다는 것은 선형 분류기로 latent vector를 잘 분리할 수 없다는 말이 되고 다른 말로 하면 linear 하게 분포되어 있지 않다는 의미입니다.
결과적으로 이러한 entropy가 낮을수록 더 선형적으로 분류가 잘 된다고 이해할 수 있습니다.
table 4를 확인해 보시면 알 수 있듯이 우리가 전통적인 GAN을 쓰든 혹은 style based GAN을 쓰든 항상 w vector를 사용할 때가 훨씬 separability가 높은 걸 확인할 수 있습니다.
즉 mapping layer를 사용해서 mapping을 거친 이후에 w space에서 interpolation을 할 때가 성능이 훨씬 좋은 성능을 낼 수 있다는 걸 보여주는 겁니다.
숫자는 mapping network의 깊이를 의미합니다. 기본적으로 mapping network에 layer가 많으면 많을수록 조금 더 좋은 성능이 나오는 걸 확인할 수 있습니다.
이러한 결과는 우리가 전통적인 generator의 architecture를 사용하든 style based generator를 사용하든, 별도의 mapping network를 사용할 때 훨씬 linear 한 latent의 sub-space를 갖도록 만들 수 있다는 걸 알 수 있습니다.
5. Conclusion
결과적으로 본 논문에서는 styleGAN을 제안하고 styleGAN은 전통적인 GAN보다 훨씬 좋은 성능을 내는 걸 확인할 수 있습니다. 전통적인 GAN의 style based architecture보다 모든 면에서 훨씬 더 우수한 편이라고 표현할 수 있으며, 다양한 metric을 통해서 입증합니다.
또한 본 논문의 큰 장점이라고 할 수 있는 각각의 high-level 특징들이 잘 분리되고, stochastic variation 또한 control이 가능하며, 실제로 latent space 상에서 적절히 각각의 vector들이 선형적으로 분리되는 것 또한 확인할 수 있었습니다.
추가적으로 본 논문에서 제안한 perceptual path length라는 metric 자체를 loss 함수로 구성해서 그 metric 자체를 줄이도록 학습 과정에서 사용할 수도 있을 것입니다.
+ Appendix
truncation trick
위에서 언급했듯이 논문에서는 안정적이고 quality 높은 이미지를 얻기 위해서 truncation trick을 사용했습니다.
low density 영역에서 샘플링을 진행하면 덜 그럴싸한 이미지가 나올 확률이 높아지기 때문에 평균 latent vector에 가까워질 수 있도록 해서, 이를 truncation을 진행해서 보다 그럴싸한 이미지를 만들어 낼 수 있다는 것입니다.
truncation parameter ψ 값을 0에 가깝게 만들수록 완전히 평균 이미지로 잘라내기가 수행되기 때문에 항상 동일한 평균적인 이미지가 나오고, 이 값이 1에 가까울수록 truncation 제약 조건이 사라지게 됩니다.
즉 truncation parameter ψ 값이 1에 가까울수록 truncation을 진행하지 않는 거고, 0에 가까울수록 truncation을 많이 진행하는 것 입니다.
C. Hyperparameters and training details
- Tesla V100 GPU 8장, 일주일 정도 학습 진행
- 원본 PGGAN 논문에서는 4x4 크기에서 출발, 본 논문에서는 8x8부터 출발해서 layer 늘림
- latent vector인 z와 w는 각각 512차원
D. Training convergence
D에서는 전통적인 방법과 본 논문의 style based GAN과 학습이 진행되는 과정에서 FID와 path length가 얼마나 차이가 나는지를 보여주고 있습니다. 참고로 두 설정 모두에서 R1 regularization이 사용되었습니다.
그래프를 보면 알 수 있듯이 훈련이 진행됨에 따라 FID 값은 천천히 감소했으며, 이는 더 많은 이미지를 훈련에 사용하기로 결정한 이유입니다(1200만 이미지에서 2500만 이미지로 증가).
이러한 양상은 FID가 증가함에 따라서 더욱 그럴싸한 이미지가 만들어질 수 있음에 따라서 linearly separable 한 특징은 상대적으로 특징들이 더욱 entangle 될 수 있다는 점을 보여주고 있는 것입니다.
하지만, path length는 해상도가 1024x1024로 완전히 올라간 후에도 천천히 증가했습니다. Path length는 생성된 이미지의 복잡성을 나타내는 지표이기 때문에 이는 FID가 개선될수록 이미지는 더 entangle 된다는 것을 의미합니다. 일종의 trade-off 관계에 있다고 할 수 있습니다.
따라서, 앞으로의 연구에서 이 복잡성이 피할 수 없는 것인지, 아니면 FID를 유지하면서 path length를 줄일 수 있는 방법이 있는지 알아보는 것이 흥미로운 주제가 될 것이라 언급합니다.
E. Other datasets
왼쪽에 보이는 그림은 LSUN bedroom 데이터셋, 오른쪽은 LSUN 자동차 데이터셋입니다.
본 논문 저자들은 FFHQ를 학습할 때와 마찬가지의 setup으로 두 데이터 셋에 대해서도 학습을 진행하였고, 그 결과 FFHQ를 이용해 학습을 진행했을 때와 유사한 속성들이 잘 드러났다고 말합니다.
예를 들어 bedroom 데이터셋의 경우 coarse style을 변경하게 되면 카메라의 구도와 같은 정보가 바뀌게 되고, middle style의 정보를 바꾸게 되면 특정 가구와 같은 정보가 바뀌며, fine style을 바꾸게 되면 색상 변화나 재질과 같은 부분이 많이 바뀌는 걸 확인할 수 있습니다.
Reference
https://www.youtube.com/watch?v=HXgfw3Z5zRo
'ML & DL > GAN' 카테고리의 다른 글
| StyleGAN2-ADA 학습 튜토리얼 (AHFQ-v2 Dataset 사용) (0) | 2024.10.27 |
|---|---|
| loss 값이 nan이 되는 이유 및 오류 해결(feat. StyleGAN) (0) | 2024.10.22 |
| CycleGAN 모델 파라미터 정리 (0) | 2024.07.31 |
| 쉽게 설명하는 CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 논문 리뷰 (5) | 2024.06.11 |