
본 논문에서는 transportation에 관련한 DRL 적용 리뷰를 다룬다.
transportation 분야를 총 7가지로 나누는데 이는 다음과 같다.
1) autonomous driving
2) energy efficient driving
3) adaptive traffic signal control
4) other types of traffic control
5) vehicle routing optimization
6) rail transportation
7) maritime transportation
본인은 hybrid ship의 에너지 절감에 관심이 많기 때문에 2번과 7번 부분을 정리하였다.
Highlights
- 빠른 발전과 검토 부족을 감안하여 교통 분야의 DRL 연구를 검토
- 확인된 7가지 영역에서 교통 분야에 대한 DRL 적용 및 적응을 검토
- 교통과 관련된 DRL의 적용 가능성, 강점 및 단점에 대해 논의
- 공통적인 문제와 애플리케이션별 문제를 식별하고 향후 연구 방향 제시
- 실제 DRL 구현을 위해 사용 가능한 플랫폼 및 기능에 대한 정보 제공
Abstract
- 교통 문제 해결을 위해 심층 강화 학습(DRL)을 적용하고 조정하는 것은 새롭게 떠오르는 분야
- 빠른 성장에 비해 DRL 적용 및 적응에 대한 검토 부족
- 2016년부터 2020년까지 발표된 총 155편의 관련 논문 검토하여 교통 연구 분야의 DRL 방법론 기초 소개 및 성과 제시
- 검토를 바탕으로 교통 분야의 적용 가능성, 장단점, 문제점, 향후 DRL 연구 방향성 종합, 가능한 연구 소스에 대한 논의 정리
Deep reinforcement learning in transportation research
Energy efficient driving
- 전기차(EV)의 중요성
- 전기차(EV)는 운송에서 화석 연료 사용과 배기가스 배출을 줄이는 데 상당한 잠재력을 가지고 있음.
- 특히 하이브리드 전기차(HEV)는 내연기관과 전기 모터의 장점을 결합하여 배기가스 배출을 줄이는 동시에 짧은 주행 거리 문제를 해결함.
- 따라서 HEV의 에너지 효율을 최적화하기 위해 에너지 관리 시스템(EMS)을 설계하는 것이 중요함.
- 강화 학습(DRL)을 통한 HEV 에너지 관리
- DRL은 다양한 HEV 유형에서 에너지 관리를 지원하는 데 유망한 결과를 보여줌. 여기에는 직병렬 플러그인 하이브리드 전기 버스, 전력 분할 하이브리드 전기 버스, 하이브리드 전기 궤도 차량, 다중 배터리 기반 EV, 하이브리드 전기 버스, 플러그인 HEV 등이 포함됨.
- DRL 연구는 기존의 규칙 기반 및 최적화 기반 접근 방식의 한계를 극복하는 것을 목표로 함. 이들은 전문가 지식, 주행 주기 및 도로에 대한 포괄적인 정보, 주행 주기 예측이 필요함.
- DRL은 차량 동역학 및 차량-도로 상호 작용을 기반으로 전기-연료 분할을 최적으로 결정하도록 에이전트를 학습시킴.
- reward 설계
- DRL의 보상 설계는 연료 소비율과 배터리의 상태(SoC)를 추적하여 에너지 사용과 절약을 고려함.
- 또한, 주행 거리의 변화도 HEV last-mile delivery 맥락에서 보상 설계에 포함됨.
- state space
- 에너지 효율적 주행을 위해 가장 중요한 정보는 차량 동역학(속도 및 가속도) 및 에너지 상태(전력 수요 및 SoC)임.
- 주행 거리, 목적지까지의 거리, 미래 예상 거리, 도로 조건(경사 및 지형) 등 외부 정보도 상태 공간에 포함될 수 있음.
- action space
- action space 설계는 서로 다른 전원 간 에너지 사용 최적화에 중점을 둠.
- 일부 연구는 내연기관의 전원 공급 변경을, 다른 연구는 전기 모터의 에너지 출력을 변경하는 방법을 다룸.
- 여러 배터리 간의 균형을 유지하는 접근 방식도 있음.
- DRL 알고리즘
- actor-critic 기반 DDPG 알고리즘은 continuous action space 처리에 사용되며, DQN, dueling DQN, double Q-learning도 성공적으로 적용됨.
- DRL 훈련은 주로 시뮬레이션 플랫폼에서 이루어지며, 일부는 실제 주행 데이터를 사용함.
- 결론
- DRL 기반 에너지 관리 시스템은 HEV의 에너지 효율성과 관리 안정성을 향상시키는 데 중요한 역할을 하며, 이를 통해 배출량 감소와 에너지 절약을 실현할 수 있음.
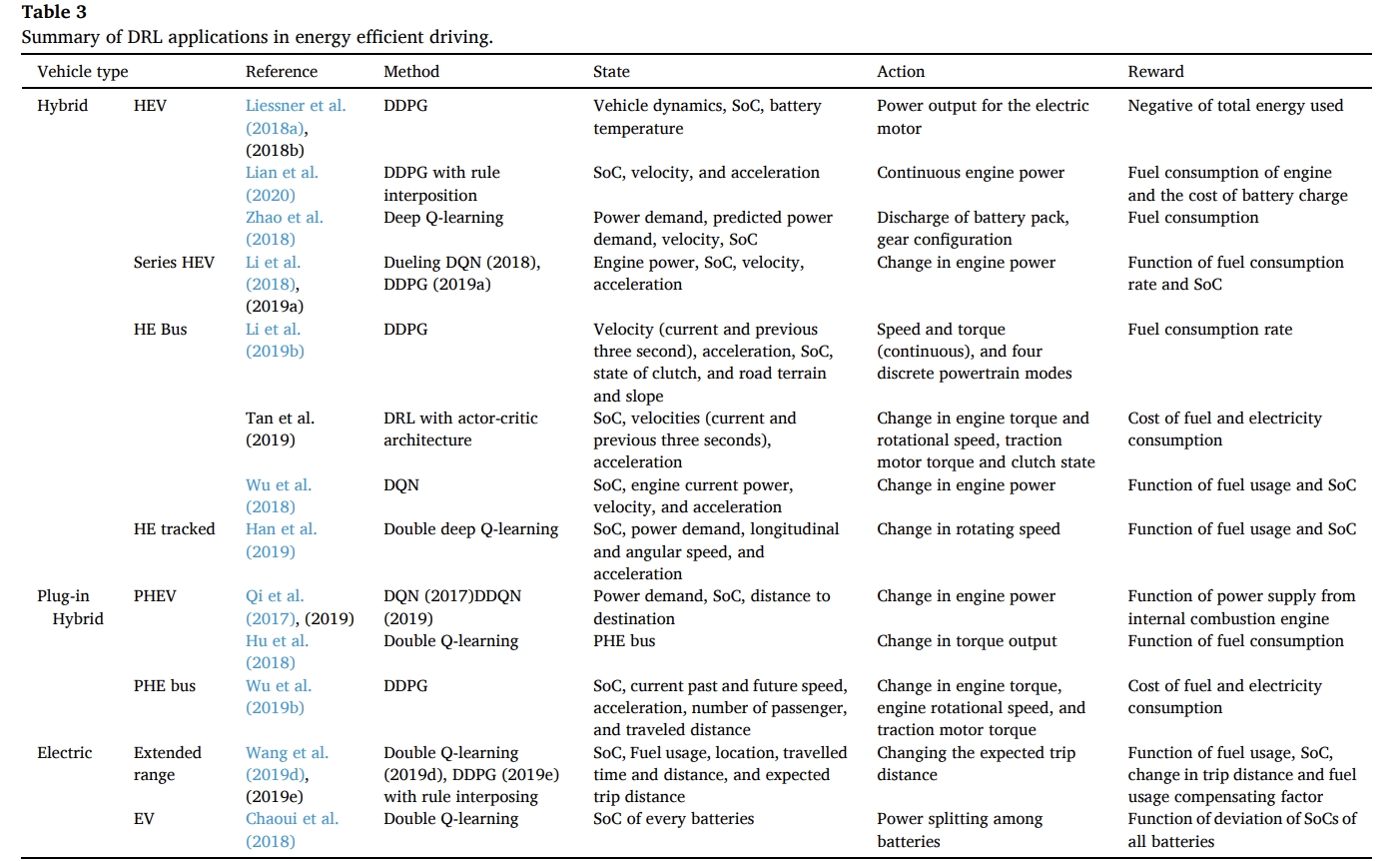
많이 사용되는 알고리즘
- DDPG, DPN, DDQN, Dueling DQN
hybrid를 중심으로 ref마다 state, action과 reward가 구체적으로 어떻게 정의되어 있는지 확인 후 정리하였다.
- state
- n_wheel: rotation speed at the wheel
- T_wheel: torque at the wheel
- gear: direct output of the driver model
- SOC
- T_bat: battery temperature
- D: internal vehicle model derating variable
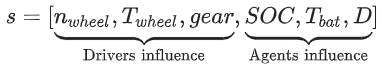
- action
- T_em: torque demand of the electric machine
- C_cool: cooling control variable
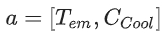
- reward function
- E_che: vehicle model output fuel consumption을 chemical energy consumption로 변환한 값
- E_el: electrical energy consumption
- state
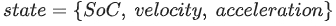
- action
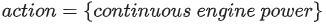
- reward function
- fuel(t): instantaneous fuel consumption of engine
- (SoC_ref - SoC(t))^2: cost of battery charge sustaining
- SoC_ref: SoC reference value while maintaining battery charge-sustaining
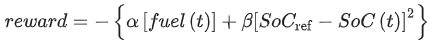
- state
- P_dem: power demand for propelling the HEV
- v: vehicle speed
- q: amount of charge stored in the battery pack
- pre: predicted power demand
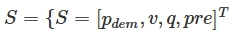
- action
- i: the discharging current of the battery pack
- R(j): the gear ratio
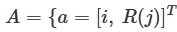
- reward function
- T: the length of a time slot
- m_f: the fuel consumption rate in that time slot
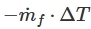
- state
- 𝑃_𝑒𝑛𝑔: power of the engine
- SoC: SoC of the battery pack
- v: velocity
- acc: acceleration
𝑆 = {𝑃𝑒𝑛𝑔, 𝑆𝑜𝐶, 𝑣, 𝑎𝑐𝑐}
- action
𝐴 = {−5kW,−1kW, 0kW, 1kW, 5kW, 25kW, engine_off}.
- reward function
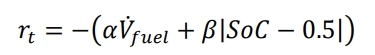
- state
- d: travel distance
- ΔSoC: SoC(k) - SoC_ref(k)
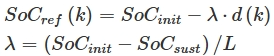
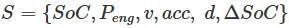
- action
- ΔP_eng: the increment or decrement value of P_eng
- −10 kW/s to 10 kW/s로 제한
- when ΔP_eng is smaller than −4 kW/s, the engine will be shut off
- ΔP_eng: the increment or decrement value of P_eng
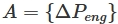
- reward function
- Blended Mode: 배터리 SoC를 일정하게 줄이면서 연료 소비 최소화
- ΔSoC: SoC 변화량
- m_fuel: 연료 소모량
- φ: factor of SoC deviation
- χ: factor of fuel consumption rate
- basic principle for parameter tuning of φ and χ is to improve the fuel economy as much as possible while ensuring that the trained strategy can always meet SoC requirements; in this paper, φ and χ are set to be 50 and 150 respectively after repeated tuning.
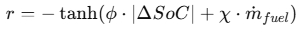
- Charge Sustaining Mode : SoC를 특정 수준(SoC_{sust})에서 유지하는 것이 목표
- SoC_sust=0.2
- φ: factor of SoC deviation
- χ: factor of fuel consumption rate
- where φ and χ are set to be 40 and 36 respectively after repeated tuning.
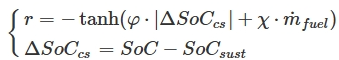
- state
- P_e: engine current power
- V: bus velocity
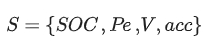
- action
- 6 options: increase 1 kW, remain unchanged, decrease 1 kW, increase 20 kW, increase 40 kW and set 0 kW (shut down engine)
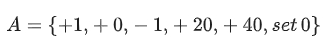
- reward function
- dfuel/dt: engine fuel consumption rate in specific speed and torque
- α and β: 명시 X
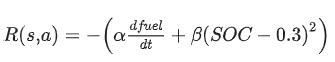
- state
- P_req: power requested
- v: longitudinal speed
- w: angular speed
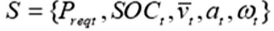
- action: to operate the rotating speed
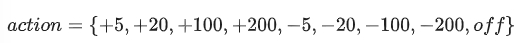
- reward function
- Wu et al. (2018) 와 동일
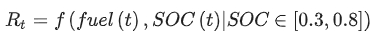
- state
- P_whl: power demand at wheel
- B_soc: battery pack’s state-of-charge (0.2~0.8)
- D_des: distance to the destination

- action: 24 power level output from engine
- reward function
- P_ICE: power supply from ICE(internal combustion engine)
- P: numerical penalty, given as the maximum power supply from ICE
- M_in_{P_ICE}: minimum nonzero value of ICE power supply
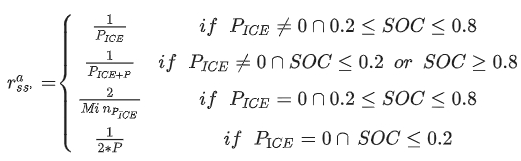
- state
- T_dem: total required torque
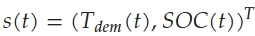
- action
- n=24
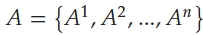
- reward function
- C_ICE: instantaneous fuel consumption value of the ICE
- C: numerical penalty, as well as the maximum instantaneous power supply from the ICE
- M_in_{C_ICE}: minimum nonzero value of the ICE instantaneous fuel consumption value
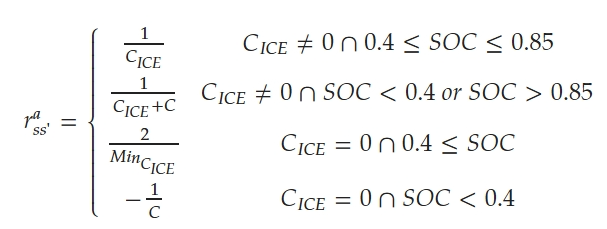
- state
- v_t: speed
- acc_t: acceleration
- p_t: number of passenger
- d_t: traveled distance of the PHEB at time t
- vs_t^l1: PHEB가 주행 중인 links 센서에 기록된 속도
- vs_t^l2: 주행할 속도
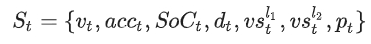
- action
- T_eng: engine torque
- W_eng: engine rational speed
- T_mot: traction motor torque
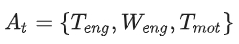
- reward function
- v_fuel: fuel consumption
- Q_bat: battery capacity
- Price_fuel: fuel price (6.5(CNY/L))
- Price_electric: electric price (0.97(CNY/KW.h))
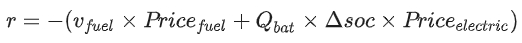
Maritime transportation
막상 확인하니 해상 운송 분야에서는 하이브리드 선박 연료 소모관련 내용은 없었지만, 관련 분야와 알고리즘 등을 볼 겸 같이 정리해보았다.
- DRL의 해양 운송 적용
- Autonomous Ship (AS) 운항의 맥락에서 DRL 응용이 주로 이루어짐. 특히 AS path following 및 collision avoidance 문제에서 DRL의 활용이 두드러짐.
- 기존 분석적 방법(예: 모델 예측 제어)은 동적이고 복잡한 AS 운전 환경에서는 실용적으로 적용하기 어려움. 이에 DRL은 대안으로 주목받고 있으며, 일부 성공 사례도 있음.
- AS 경로 추종 문제
- DRL을 적용한 연구에서 rudder angle, course angel, 프로펠러 회전을 동작으로 고려함.
- 보상 함수는 선박이 미리 정의된 경로에서 벗어난 정도를 반영함. 예를 들어, Martinsen과 Lekkas(2018), Woo 외(2019)는 경로 이탈 오류로 보상을 정의하고, Rejaili와 Figueiredo(2018)는 편차에 대한 벌점을 부여하여 보상을 정의함.
- 상태 공간은 경로 가이드라인, 선박 질량 중심과 가이드라인 사이 거리, 선박의 종축과 가이드라인 사이 각도로 나타내며, 선박 속도 및 각속도도 포함됨.
- 경로 추종과 충돌 회피의 동시 모델링
- model-based and model-free 제어 방법이 연구되었으며, DRL은 주로 model-free 방법에서 적용됨.
- 정적 장애물 회피에 중점을 둔 연구에서 안전 관련 보상이 정의됨. 예를 들어, Sawada(2019)는 장애물과의 안전 통과 거리를 보상으로 사용하며, 다른 연구자들은 충돌 횟수를 고려함.
- 상태 공간에는 선박 위치, 방향, 회전율, 장애물과의 거리가 포함되며, 선박 폭 및 길이가 추가로 고려됨.
- 정적 및 동적 장애물 처리
- 환경적 방해 요소와 같은 동적 장애물까지 고려하는 연구가 존재함. 이 연구들에서는 매 시간 단계마다 방향 조정 결정을 내리며, 이는 선박 및 장애물 위치에 의해 결정됨.
- state space에는 속도, 각속도, 전진 및 횡진 등이 포함됨. Zhao와 Roh(2019)를 제외한 모든 연구는 single-agent DQN을 사용하여 단일 선박 내비게이션을 다룸.
- 항만 관리에서의 DRL 적용
- Shen 외(2017)는 중국 Ningbo 항만에서 크레인 스케줄링을 위해 DQN을 사용함.
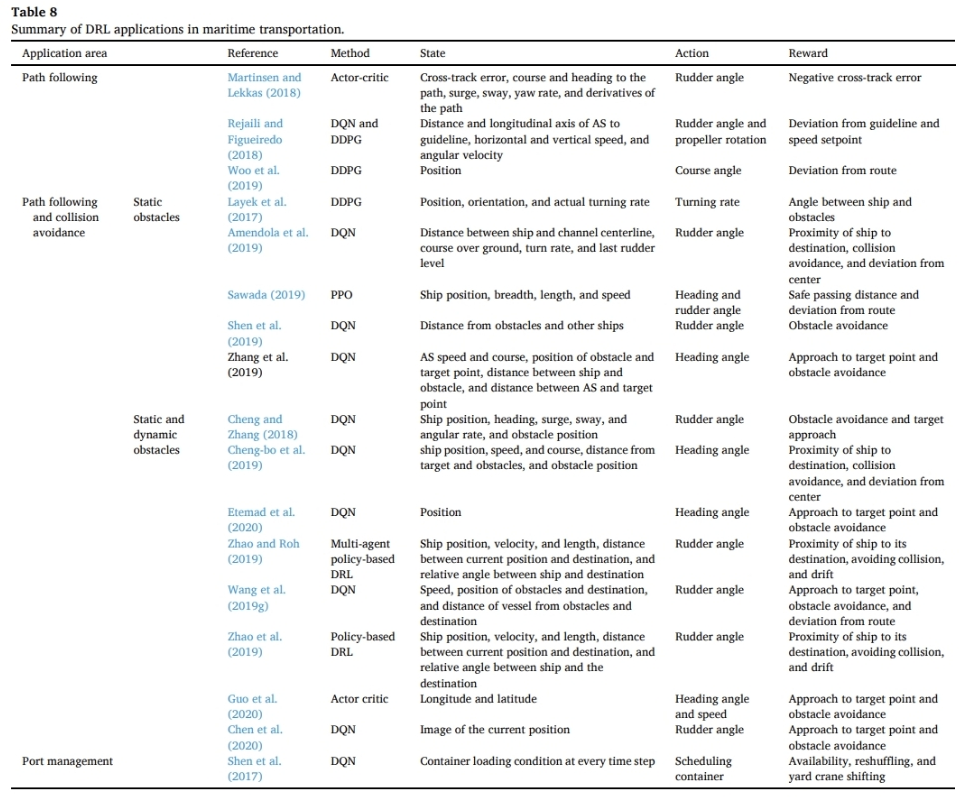
- 연구 요약
- 표 8은 AS 경로 추종, 경로 추종 및 충돌 회피, 항만 관리에 대한 연구를 요약함.
- 연구들은 응용 분야, 사용된 방법, 상태, 동작, 보상 명세에 따라 분류됨.
- 모든 연구에서 환경은 fully observable하다고 가정함.
'ML & DL > RL' 카테고리의 다른 글
본 논문에서는 transportation에 관련한 DRL 적용 리뷰를 다룬다.
transportation 분야를 총 7가지로 나누는데 이는 다음과 같다.
1) autonomous driving
2) energy efficient driving
3) adaptive traffic signal control
4) other types of traffic control
5) vehicle routing optimization
6) rail transportation
7) maritime transportation
본인은 hybrid ship의 에너지 절감에 관심이 많기 때문에 2번과 7번 부분을 정리하였다.
Highlights
- 빠른 발전과 검토 부족을 감안하여 교통 분야의 DRL 연구를 검토
- 확인된 7가지 영역에서 교통 분야에 대한 DRL 적용 및 적응을 검토
- 교통과 관련된 DRL의 적용 가능성, 강점 및 단점에 대해 논의
- 공통적인 문제와 애플리케이션별 문제를 식별하고 향후 연구 방향 제시
- 실제 DRL 구현을 위해 사용 가능한 플랫폼 및 기능에 대한 정보 제공
Abstract
- 교통 문제 해결을 위해 심층 강화 학습(DRL)을 적용하고 조정하는 것은 새롭게 떠오르는 분야
- 빠른 성장에 비해 DRL 적용 및 적응에 대한 검토 부족
- 2016년부터 2020년까지 발표된 총 155편의 관련 논문 검토하여 교통 연구 분야의 DRL 방법론 기초 소개 및 성과 제시
- 검토를 바탕으로 교통 분야의 적용 가능성, 장단점, 문제점, 향후 DRL 연구 방향성 종합, 가능한 연구 소스에 대한 논의 정리
Deep reinforcement learning in transportation research
Energy efficient driving
- 전기차(EV)의 중요성
- 전기차(EV)는 운송에서 화석 연료 사용과 배기가스 배출을 줄이는 데 상당한 잠재력을 가지고 있음.
- 특히 하이브리드 전기차(HEV)는 내연기관과 전기 모터의 장점을 결합하여 배기가스 배출을 줄이는 동시에 짧은 주행 거리 문제를 해결함.
- 따라서 HEV의 에너지 효율을 최적화하기 위해 에너지 관리 시스템(EMS)을 설계하는 것이 중요함.
- 강화 학습(DRL)을 통한 HEV 에너지 관리
- DRL은 다양한 HEV 유형에서 에너지 관리를 지원하는 데 유망한 결과를 보여줌. 여기에는 직병렬 플러그인 하이브리드 전기 버스, 전력 분할 하이브리드 전기 버스, 하이브리드 전기 궤도 차량, 다중 배터리 기반 EV, 하이브리드 전기 버스, 플러그인 HEV 등이 포함됨.
- DRL 연구는 기존의 규칙 기반 및 최적화 기반 접근 방식의 한계를 극복하는 것을 목표로 함. 이들은 전문가 지식, 주행 주기 및 도로에 대한 포괄적인 정보, 주행 주기 예측이 필요함.
- DRL은 차량 동역학 및 차량-도로 상호 작용을 기반으로 전기-연료 분할을 최적으로 결정하도록 에이전트를 학습시킴.
- reward 설계
- DRL의 보상 설계는 연료 소비율과 배터리의 상태(SoC)를 추적하여 에너지 사용과 절약을 고려함.
- 또한, 주행 거리의 변화도 HEV last-mile delivery 맥락에서 보상 설계에 포함됨.
- state space
- 에너지 효율적 주행을 위해 가장 중요한 정보는 차량 동역학(속도 및 가속도) 및 에너지 상태(전력 수요 및 SoC)임.
- 주행 거리, 목적지까지의 거리, 미래 예상 거리, 도로 조건(경사 및 지형) 등 외부 정보도 상태 공간에 포함될 수 있음.
- action space
- action space 설계는 서로 다른 전원 간 에너지 사용 최적화에 중점을 둠.
- 일부 연구는 내연기관의 전원 공급 변경을, 다른 연구는 전기 모터의 에너지 출력을 변경하는 방법을 다룸.
- 여러 배터리 간의 균형을 유지하는 접근 방식도 있음.
- DRL 알고리즘
- actor-critic 기반 DDPG 알고리즘은 continuous action space 처리에 사용되며, DQN, dueling DQN, double Q-learning도 성공적으로 적용됨.
- DRL 훈련은 주로 시뮬레이션 플랫폼에서 이루어지며, 일부는 실제 주행 데이터를 사용함.
- 결론
- DRL 기반 에너지 관리 시스템은 HEV의 에너지 효율성과 관리 안정성을 향상시키는 데 중요한 역할을 하며, 이를 통해 배출량 감소와 에너지 절약을 실현할 수 있음.
많이 사용되는 알고리즘
- DDPG, DPN, DDQN, Dueling DQN
hybrid를 중심으로 ref마다 state, action과 reward가 구체적으로 어떻게 정의되어 있는지 확인 후 정리하였다.
- state
- n_wheel: rotation speed at the wheel
- T_wheel: torque at the wheel
- gear: direct output of the driver model
- SOC
- T_bat: battery temperature
- D: internal vehicle model derating variable
- action
- T_em: torque demand of the electric machine
- C_cool: cooling control variable
- reward function
- E_che: vehicle model output fuel consumption을 chemical energy consumption로 변환한 값
- E_el: electrical energy consumption
- state
- action
- reward function
- fuel(t): instantaneous fuel consumption of engine
- (SoC_ref - SoC(t))^2: cost of battery charge sustaining
- SoC_ref: SoC reference value while maintaining battery charge-sustaining
- state
- P_dem: power demand for propelling the HEV
- v: vehicle speed
- q: amount of charge stored in the battery pack
- pre: predicted power demand
- action
- i: the discharging current of the battery pack
- R(j): the gear ratio
- reward function
- T: the length of a time slot
- m_f: the fuel consumption rate in that time slot
- state
- 𝑃_𝑒𝑛𝑔: power of the engine
- SoC: SoC of the battery pack
- v: velocity
- acc: acceleration
𝑆 = {𝑃𝑒𝑛𝑔, 𝑆𝑜𝐶, 𝑣, 𝑎𝑐𝑐}
- action
𝐴 = {−5kW,−1kW, 0kW, 1kW, 5kW, 25kW, engine_off}.
- reward function
- state
- d: travel distance
- ΔSoC: SoC(k) - SoC_ref(k)
- action
- ΔP_eng: the increment or decrement value of P_eng
- −10 kW/s to 10 kW/s로 제한
- when ΔP_eng is smaller than −4 kW/s, the engine will be shut off
- ΔP_eng: the increment or decrement value of P_eng
- reward function
- Blended Mode: 배터리 SoC를 일정하게 줄이면서 연료 소비 최소화
- ΔSoC: SoC 변화량
- m_fuel: 연료 소모량
- φ: factor of SoC deviation
- χ: factor of fuel consumption rate
- basic principle for parameter tuning of φ and χ is to improve the fuel economy as much as possible while ensuring that the trained strategy can always meet SoC requirements; in this paper, φ and χ are set to be 50 and 150 respectively after repeated tuning.
- Charge Sustaining Mode : SoC를 특정 수준(SoC_{sust})에서 유지하는 것이 목표
- SoC_sust=0.2
- φ: factor of SoC deviation
- χ: factor of fuel consumption rate
- where φ and χ are set to be 40 and 36 respectively after repeated tuning.
- state
- P_e: engine current power
- V: bus velocity
- action
- 6 options: increase 1 kW, remain unchanged, decrease 1 kW, increase 20 kW, increase 40 kW and set 0 kW (shut down engine)
- reward function
- dfuel/dt: engine fuel consumption rate in specific speed and torque
- α and β: 명시 X
- state
- P_req: power requested
- v: longitudinal speed
- w: angular speed
- action: to operate the rotating speed
- reward function
- Wu et al. (2018) 와 동일
- state
- P_whl: power demand at wheel
- B_soc: battery pack’s state-of-charge (0.2~0.8)
- D_des: distance to the destination
- action: 24 power level output from engine
- reward function
- P_ICE: power supply from ICE(internal combustion engine)
- P: numerical penalty, given as the maximum power supply from ICE
- M_in_{P_ICE}: minimum nonzero value of ICE power supply
- state
- T_dem: total required torque
- action
- n=24
- reward function
- C_ICE: instantaneous fuel consumption value of the ICE
- C: numerical penalty, as well as the maximum instantaneous power supply from the ICE
- M_in_{C_ICE}: minimum nonzero value of the ICE instantaneous fuel consumption value
- state
- v_t: speed
- acc_t: acceleration
- p_t: number of passenger
- d_t: traveled distance of the PHEB at time t
- vs_t^l1: PHEB가 주행 중인 links 센서에 기록된 속도
- vs_t^l2: 주행할 속도
- action
- T_eng: engine torque
- W_eng: engine rational speed
- T_mot: traction motor torque
- reward function
- v_fuel: fuel consumption
- Q_bat: battery capacity
- Price_fuel: fuel price (6.5(CNY/L))
- Price_electric: electric price (0.97(CNY/KW.h))
Maritime transportation
막상 확인하니 해상 운송 분야에서는 하이브리드 선박 연료 소모관련 내용은 없었지만, 관련 분야와 알고리즘 등을 볼 겸 같이 정리해보았다.
- DRL의 해양 운송 적용
- Autonomous Ship (AS) 운항의 맥락에서 DRL 응용이 주로 이루어짐. 특히 AS path following 및 collision avoidance 문제에서 DRL의 활용이 두드러짐.
- 기존 분석적 방법(예: 모델 예측 제어)은 동적이고 복잡한 AS 운전 환경에서는 실용적으로 적용하기 어려움. 이에 DRL은 대안으로 주목받고 있으며, 일부 성공 사례도 있음.
- AS 경로 추종 문제
- DRL을 적용한 연구에서 rudder angle, course angel, 프로펠러 회전을 동작으로 고려함.
- 보상 함수는 선박이 미리 정의된 경로에서 벗어난 정도를 반영함. 예를 들어, Martinsen과 Lekkas(2018), Woo 외(2019)는 경로 이탈 오류로 보상을 정의하고, Rejaili와 Figueiredo(2018)는 편차에 대한 벌점을 부여하여 보상을 정의함.
- 상태 공간은 경로 가이드라인, 선박 질량 중심과 가이드라인 사이 거리, 선박의 종축과 가이드라인 사이 각도로 나타내며, 선박 속도 및 각속도도 포함됨.
- 경로 추종과 충돌 회피의 동시 모델링
- model-based and model-free 제어 방법이 연구되었으며, DRL은 주로 model-free 방법에서 적용됨.
- 정적 장애물 회피에 중점을 둔 연구에서 안전 관련 보상이 정의됨. 예를 들어, Sawada(2019)는 장애물과의 안전 통과 거리를 보상으로 사용하며, 다른 연구자들은 충돌 횟수를 고려함.
- 상태 공간에는 선박 위치, 방향, 회전율, 장애물과의 거리가 포함되며, 선박 폭 및 길이가 추가로 고려됨.
- 정적 및 동적 장애물 처리
- 환경적 방해 요소와 같은 동적 장애물까지 고려하는 연구가 존재함. 이 연구들에서는 매 시간 단계마다 방향 조정 결정을 내리며, 이는 선박 및 장애물 위치에 의해 결정됨.
- state space에는 속도, 각속도, 전진 및 횡진 등이 포함됨. Zhao와 Roh(2019)를 제외한 모든 연구는 single-agent DQN을 사용하여 단일 선박 내비게이션을 다룸.
- 항만 관리에서의 DRL 적용
- Shen 외(2017)는 중국 Ningbo 항만에서 크레인 스케줄링을 위해 DQN을 사용함.
- 연구 요약
- 표 8은 AS 경로 추종, 경로 추종 및 충돌 회피, 항만 관리에 대한 연구를 요약함.
- 연구들은 응용 분야, 사용된 방법, 상태, 동작, 보상 명세에 따라 분류됨.
- 모든 연구에서 환경은 fully observable하다고 가정함.