
(2018) [BCQ] Off-Policy Deep Reinforcement Learning without Exploration
https://arxiv.org/abs/1812.02900
Scott Fujimoto, David Meger, Doina Precup
Abstract
- 많은 강화학습 응용은 고정된 데이터 배치에서 학습해야 하며, 추가적인 데이터 수집이 불가능함.
- 표준 Off-policy 알고리즘(DQN, DDPG)은 현재 정책과 상관된 데이터가 없으면 학습할 수 없으며, 고정된 배치 설정에서 효과적이지 않음.
- Batch-Constrained Reinforcement Learning을 제안하며, 에이전트가 행동 공간을 제한하여 주어진 데이터와 On-policy에 가깝게 행동하도록 유도함.
- BCQ 알고리즘은 연속 제어 문제에서 고정된 배치 데이터를 사용해 효과적으로 학습할 수 있는 첫 번째 알고리즘임을 입증함.
Introduction
- 배치 강화학습의 필요성
- 배치 강화학습은 고정된 데이터셋에서 학습하는 작업으로, 환경과 추가 상호작용 없이 학습함.
- 이는 데이터 수집 절차가 비용이 많이 들거나 위험하거나 시간이 많이 소요될 때 필수적인 방법임.
- 예를 들어, 로봇 제어나 의료 응용에서 데이터 수집이 비용 및 위험성이 크므로, 이러한 환경에서는 배치 강화학습이 필요함.
- Off-policy 배치 강화학습의 실질적 이점
- 배치 강화학습을 통해, 데이터 수집을 2차 제어 프로세스 (예: 인간 운영자, 모니터링된 프로그램)로 안전하게 수행할 수 있음.
- 이는 더 효율적이며 안전한 데이터 수집 절차를 가능하게 하며, 위험한 환경에서의 실시간 상호작용을 최소화함.
- 모방 학습의 한계
- 모방 학습은 행동 정책의 품질에 대한 강력한 가정이 필요하며, 이는 비최적 경로에 노출되면 실패할 수 있음.
- 또한 모방 학습은 종종 환경과의 추가 상호작용이 필요하여, 이를 보완해야 하는 경우가 많음.
- 반면, 배치 강화학습은 고정된 데이터셋에서 학습할 수 있으며, 데이터 품질에 제한을 두지 않음.
- 기존 Off-policy 알고리즘의 문제점
- 현대 Off-policy 강화학습 알고리즘은 일반적으로 데이터를 경험 재생 버퍼(replay buffer)에 저장한 후, 더 많은 데이터를 수집하기 전에 그 데이터를 사용하여 에이전트를 학습시키는 Growing Batch Learning 방식에 의존함.
- 하지만 고정된 배치 데이터를 사용할 때, 이 알고리즘들이 실패할 수 있음.
- 특히, 현재 정책과 연관되지 않은 데이터를 사용할 경우, 학습 성능이 크게 떨어짐.
- 외삽 오류의 원인 및 영향
- 외삽 오류(extrapolation error)는 보지 못한 상태-동작 쌍에 대해 Q-함수가 비현실적인 값을 예측하는 현상임.
- 이는 정책이 유도하는 데이터 분포와 배치 데이터에 포함된 분포 간의 불일치로 인해 발생함.
- 외삽 오류는 정책이 배치에 포함되지 않은 동작을 선택할 때, 올바른 가치 함수를 학습할 수 없게 만듦.
- Batch-Constrained Reinforcement Learning의 도입
- 외삽 오류를 해결하기 위해, 우리는 Batch-Constrained Reinforcement Learning을 제안함.
- 이 방법은 에이전트가 보상을 최대화하면서, 정책의 상태-동작 방문과 배치에 포함된 상태-동작 쌍 간의 불일치를 최소화하도록 학습함.
- BCQ 알고리즘의 원리
- Batch-Constrained deep Q-learning (BCQ) 알고리즘은 상태-조건부 생성 모델을 사용하여 이전에 본 동작만을 생성함.
- 이 생성 모델은 Q-네트워크와 결합되어, 배치 데이터와 유사한 가장 높은 가치의 동작을 선택함.
- BCQ는 환경과 상호작용 없이도 성공적으로 학습할 수 있도록 설계되었으며, 외삽 오류를 효과적으로 고려함.
- 실험 결과
- MuJoCo 환경에서 고차원 연속 행동 공간에서 평가한 결과, BCQ는 외삽 오류가 큰 문제로 나타나는 배치 강화학습 작업에서 우수한 성능을 보임.
- BCQ는 순수 전문가 데모뿐만 아니라 비최적 데이터가 포함된 고정 배치에서도 학습할 수 있음.
(2020) [CQL] Conservative Q-Learning for Offline Reinforcement Learning
https://arxiv.org/abs/2006.04779
Aviral Kumar, Aurick Zhou, George Tucker, Sergey Levine
Abstract
- Offline RL 알고리즘은 정적 데이터셋에서 상호작용 없이 효과적인 정책을 학습하는 것을 목표로 함.
- Offline RL에서 분포적 차이로 인해 표준 Off-policy RL 방법은 가치의 과대평가로 실패할 수 있음.
- Conservative Q-learning(CQL)은 보수적인 Q-함수를 학습하여 정책의 기대값이 실제 값보다 하한을 두도록 설계됨.
- CQL은 Bellman 오차에 Q-값 정규화를 추가하여 구현되며, 기존 deep Q-learning 및 actor-critic 방법과 호환 가능함.
- CQL은 이론적으로 정책의 값에 하한을 제공하며, 다양한 실험에서 기존 Offline RL 방법보다 2~5배 더 높은 최종 보상을 달성함.
Introduction
- RL의 최근 발전과 Offline RL의 필요성
- RL은 로봇공학, 전략 게임, 추천 시스템 등에서 유망한 성과를 거두었으나, 실제 환경에서의 상호작용은 비용이 크고 위험할 수 있음.
- Offline RL은 정적 데이터셋에서 학습하여 상호작용 없이 정책을 최적화할 수 있는 방법을 제시함.
- 그러나 정책을 수집한 데이터와 학습된 정책 간의 분포 차이로 인해 성능 저하가 발생함.
- 기존 Off-policy RL 알고리즘의 한계
- Offline 환경에서 기존 Off-policy RL 알고리즘을 직접 사용하면 분포 외 행동으로 인해 외삽 오류가 발생함.
- 이러한 오류는 과대평가된 Q-함수로 이어져 잘못된 정책 평가를 초래함.
- CQL의 제안과 핵심 아이디어
- Conservative Q-learning(CQL)은 보수적인 Q-함수를 학습하여 정책의 기대값이 실제 값보다 하한을 두도록 설계됨.
- 정책 하에서 Q-함수의 기대값에만 하한을 두는 방식으로, 점별(point-wise) 하한보다 효율적인 정책 평가를 가능하게 함.
- 상태-동작 쌍에 대한 최소화와 데이터 분포에 대한 최대화를 결합하여 Q-값을 보수적으로 추정함.
- Conservative Q-learning(CQL)은 보수적인 Q-함수를 학습하여 정책의 기대값이 실제 값보다 하한을 두도록 설계됨.
- CQL의 장점 및 실험 결과
- CQL은 복잡한 데이터셋과 고차원 시각 입력을 다룰 때 기존 방법보다 2~5배 더 높은 성능을 보임.
- 단순한 행동 복제를 능가하는 성능을 제공하는 유일한 방법임.
- CQL은 기존 온라인 RL 알고리즘에 간단하게 통합할 수 있으며, 적은 양의 코드로 구현 가능함.
(2020) [CRR] Critic Regularized Regression
https://arxiv.org/abs/2006.15134
Ziyu Wang, Alexander Novikov, Konrad Zolna, Jost Tobias Springenberg, Scott Reed, Bobak Shahriari, Noah Siegel, Josh Merel, Caglar Gulcehre, Nicolas Heess, Nando de Freitas
Abstract
- Offline RL은 사전 기록된 데이터셋을 사용하여 정책 최적화를 가능하게 하며, 데이터 수집 비용과 안전성 문제를 해결한다.
- 대부분의 off-policy 알고리즘은 고정된 데이터셋에서 학습할 때 성능이 좋지 않다.
- 본 논문에서는 critic-regularized regression(CRR) 기법을 사용한 새로운 offline RL 알고리즘을 제안한다.
- CRR은 고차원 상태 및 행동 공간에서도 확장 가능하며, 다양한 벤치마크에서 다른 최신 알고리즘보다 더 우수한 성능을 보여준다.
Introduction
- Deep RL은 여러 도전적인 도메인에서 성공을 거두었으나, 실세계 의사결정에 사용된 사례는 드물다.
- 온라인 RL은 비용, 안전성, 윤리적 문제로 인해 실세계에서 실행하기 어려운 경우가 많다.
- 많은 도메인에서 대규모의 과거 데이터가 존재하며, 이를 활용한 offline RL에 대한 관심이 커지고 있다.
- RL에서 탐색과 경험 학습을 분리하여 고정된 경험으로부터 학습할 경우 알고리즘 평가 및 비교가 용이해진다.
- 기존 off-policy RL 알고리즘은 고정된 데이터에서 실패하는 경우가 많으며, 지나치게 낙관적인 Q-추정과 데이터 외삽이 주요 원인이다.
- CRR은 value-filtering된 회귀 형태로 정책 최적화를 수행하며, actor-critic 방법에 최소한의 변경만 필요하다.
- 실험 결과, CRR은 고차원 상태 및 행동 공간에서도 우수한 성능을 보였다.
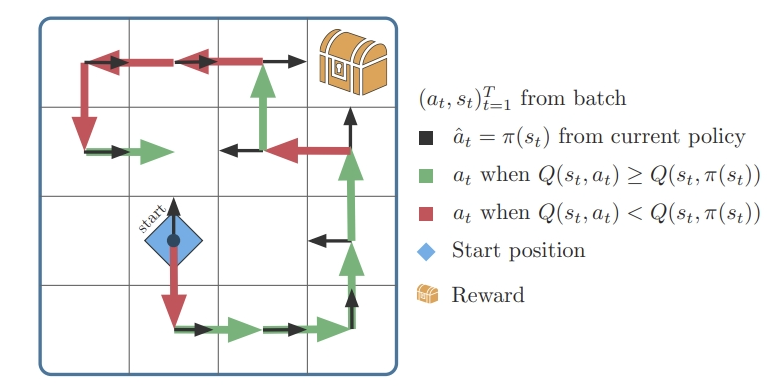
- 격자(grid): 에이전트(로봇 등)가 여러 방향으로 움직일 수 있는 환경. 에이전트는 왼쪽 아래에서 시작해(시작점, 파란 다이아몬드) 보상이 있는 상자를 찾아가야 한다.
- 화살표(초록색/빨간색): 화살표는 에이전트가 각 상태에서 취할 수 있는 행동을 나타낸다. 초록색 화살표는 좋은 행동(현재 정책보다 나은 행동)을 의미하고, 빨간색 화살표는 나쁜 행동(현재 정책보다 나쁜 행동)을 의미한다.
- 검정색 화살표: 현재 학습 중인 정책이 각 상태에서 제안하는 행동이다.
CRR 알고리즘 동작 방식
- 현재 정책의 행동(검정 화살표)과 배치에서 나온 행동(빨간색 또는 초록색 화살표)을 비교한다.
- Q값 비교: 각 상태에서 특정 행동의 가치(Q값)를 계산하여, 배치에서 나온 행동(과거 행동)이 현재 정책의 행동보다 더 나은지(Q(st, at) ≥ Q(st, π(st)))를 평가한다.
- 만약 과거 행동이 더 좋다면(초록색 화살표), 그 행동을 정책 학습에 사용한다.
- 만약 과거 행동이 더 나쁘다면(빨간색 화살표), 그 행동은 무시한다.
- 이 과정에서 나쁜 행동(빨간색 화살표)을 걸러내고 좋은 행동(초록색 화살표)만 학습에 반영하여 정책을 개선해나간다.
(2020) [PLAS] Latent Action Space for Offline Reinforcement Learning
https://arxiv.org/abs/2011.07213
Wenxuan Zhou, Sujay Bajracharya, David Held
Abstract
- Offline Reinforcement Learning의 목표는 추가적인 상호작용 없이 고정된 데이터셋에서 정책을 학습하는 것임.
- 기존의 Off-policy 알고리즘은 데이터셋 외부 동작으로 인한 외삽 오류로 인해 정적 데이터셋에서 성능이 제한적임.
- PLAS(Policy in the Latent Action Space)는 명시적인 제약 없이 정책을 데이터셋의 지원 내에서 학습하는 간단한 방법을 제안함.
- PLAS는 시뮬레이션 연속 제어 벤치마크 및 실제 로봇 변형 객체 조작 작업에서 기존 방법보다 일관되게 높은 성능을 제공함.
Introduction
- 강화학습(RL)의 성공과 한계
- 강화학습(RL)은 시뮬레이션에서 로봇 작업과 같은 여러 분야에서 큰 성과를 거두었음 [1, 2].
- 그러나 실제 세계, 특히 실제 로봇에 RL을 적용하는 데에는 여전히 제한적임.
- 주요 도전 과제: RL은 환경과의 대규모 온라인 상호작용을 요구하며, 보통 수백만 번의 타임 스텝이 필요함.
- Offline Reinforcement Learning (Offline RL)의 등장
- Offline RL, 또는 Batch RL,은 정적 데이터셋을 기반으로 정책을 최적화하는 알고리즘을 개발하는 것에 중점을 둠 [3, 4].
- 로봇공학에서의 중요성
- 데이터 수집 과정에서 더 많은 유연성을 제공함.
- 안전성을 고려하거나 더 나은 탐사 방법을 사용할 수 있음 [5].
- 데모(demonstration)를 활용할 수 있음 [6].
- Offline RL이 제공하는 추가적인 이점
- 과거 경험의 재사용: 이전 RL 실험에서 평가 궤적이나 리플레이 버퍼를 재사용할 수 있음.
- 데이터셋 공유: 정적 데이터셋은 커뮤니티 내에서 쉽게 공유될 수 있으며, 데이터셋의 크기가 확장 가능함.
- Off-policy RL의 문제점
- Off-policy RL은 훈련 절차 동안 정책에 의해 능동적으로 수집된 전이(transition)를 저장하는 리플레이 버퍼를 사용함.
- 기존 연구에서는 Off-policy RL 방법이 정적 데이터셋에 직접 적용되지 않는 이유를 지적함
- 데이터셋 외부 동작(out-of-distribution actions)으로 인한 Q-함수의 외삽 오류가 발생함 [7].
- 외삽 오류 문제와 정책 제약의 필요성
- 외삽 오류 방지를 위해서는, 정책이 데이터셋의 지원(support) 내에서 동작을 선택하도록 제한해야 함.
- 하지만 제약이 지나치게 엄격해서는 안 됨
- 과도한 제약은 정책이 행동 복제(behavior cloning)로 퇴화할 수 있음.
- 따라서, 적절한 제약 설계가 중요한 문제로 남아 있음.
- PLAS(Policy in the Latent Action Space) 방법 제안
- 우리는 명시적인 제약을 사용하지 않고, Latent Action Space에서 정책을 훈련하는 간단하면서도 효과적인 방법을 제안함.
- 데이터셋의 행동 정책(behavior policy)을 Conditional Variational Autoencoder (CVAE)로 모델링함
- 핵심 아이디어
- CVAE의 Latent Action Space에서 정책을 학습하고, 이를 디코더로 사용하여 원래의 Action Space에서 동작을 출력함.
- Latent Action Space는 구조적으로 정책을 암묵적으로 제한함.
- 장점
- 제약이 다른 최적화 구성 요소에 영향을 주지 않고 자연스럽게 충족됨.
- 행동 정책 분포의 밀도에 의해 제한받지 않음.
- PLAS의 일반화 성능 및 확장성
- PLAS는 데이터셋 내에서 일반화를 허용하며, 다양한 동작이 포함된 데이터셋에서도 일관되게 좋은 성능을 제공함.
- Q-함수의 일반화 성능이 뛰어날 때에는, 제어된 방식으로 데이터셋 외부 동작을 허용하여 성능을 향상시킴.
- 내부 분포 일반화와 외부 분포 일반화를 명시적으로 분리하여, 사용자가 방법의 일반화 범위에 대해 세부적인 제어를 할 수 있게 함.
- 실험 결과
- 우리는 PLAS를 d4rl 벤치마크 데이터셋의 연속 제어 작업과 실제 로봇 실험에 적용하였으며, 간단함에도 불구하고 이전 방법들보다 우수한 성능을 보였음.
(2021) [EDAC] Uncertainty-based offline reinforcement learning with diversified q-ensemble
https://arxiv.org/abs/2110.01548
Gaon An, Seungyong Moon, Jang-Hyun Kim, Hyun Oh Song
Abstract
- Offline RL은 정적 데이터셋에서 최적의 정책을 찾는 것을 목표로 하지만, OOD 데이터 포인트로 인한 함수 근사 오류로 어려움을 겪음.
- 기존 방법들은 정책이 주어진 데이터에 가깝게 유지되도록 제약 또는 패널티 항을 도입하지만, 행동 정책 추정이나 OOD 샘플링의 어려움이 있음.
- 본 연구는 Q-값의 신뢰도를 고려한 불확실성 기반 offline RL 방법을 제안하며, 데이터 분포 추정이나 샘플링이 필요하지 않음.
- clipped Q-learning을 사용해 OOD 데이터에 대한 예측 불확실성을 패널티화하는 방법을 제시하고, Q-네트워크의 수를 늘려 성능을 향상시킴.
- 제안된 앙상블-다양화된 액터-크리틱 알고리즘은 적은 수의 앙상블 네트워크로도 D4RL 벤치마크에서 최첨단 성능을 달성함.
Introduction
- 심층 강화학습(Deep RL)의 성공 사례
- 로봇공학, 추천 시스템, 전략 게임 등의 분야에서 심층 강화학습(Deep RL)은 주목할 만한 성공을 거둠 [20], [6], [26].
- 이러한 성공은 복잡한 작업에서 심층 신경망의 강력한 학습 능력을 보여줌.
- 능동 학습 절차의 한계
- 대부분의 강화학습(RL) 알고리즘은 능동적 학습 절차를 따름.
- 즉, 훈련 과정에서 에이전트가 환경과 능동적으로 상호작용해야 함.
- 이 시행착오 방식은 실제 응용에서 여러 문제를 일으킬 수 있음.
- 예: 자율주행이나 헬스케어에서는 탐색 중 발생하는 실수나 오류가 에이전트나 환경에 심각한 손상을 초래할 수 있음 [19].
- 대부분의 강화학습(RL) 알고리즘은 능동적 학습 절차를 따름.
- Offline RL의 등장
- Offline RL(배치 RL)은 이미 수집된 데이터셋만을 사용해 정책을 학습함으로써, 추가적인 환경과의 상호작용 없이 문제를 해결하려는 접근임 [2], [11], [19].
- Offline RL은 실제 환경에서의 데이터를 기반으로 RL 문제를 해결할 수 있는 데이터 기반 접근법으로 매우 유망함.
- Offline RL의 알고리즘적 도전
- 최근 연구에 따르면, Offline RL은 몇 가지 새로운 알고리즘적 도전에 직면함 [19].
- 일반적으로 데이터셋이 충분하지 않으면, vanilla RL 알고리즘은 외삽 오류(extrapolation error)로 인해 OOD(Out-of-Distribution) 상태-동작 쌍의 Q-값을 과대평가하여 성능이 크게 저하됨 [15].
- 기존 Offline RL 방법의 접근 방식
- 대부분의 offline RL 방법은 기존 RL 알고리즘에 제약이나 패널티 항을 추가하여 보수적인 학습을 유도함.
- 예를 들어, 일부 연구는 정책이 데이터 수집에 사용된 행동 정책과 가깝게 유지되도록 정규화를 적용함 [11], [15].
- 다른 연구는 OOD 상태-동작 쌍의 Q-값에 패널티를 부여하여, Q-값을 비관적으로 만들도록 함 [16].
- 대부분의 offline RL 방법은 기존 RL 알고리즘에 제약이나 패널티 항을 추가하여 보수적인 학습을 유도함.
- 기존 방법의 한계
- 행동 정책을 추정하거나 OOD 데이터에서 샘플링을 요구하는 기존 방법들은 추정의 어려움과 비효율성을 겪음.
- 또한, 이러한 방법들은 Q-함수 네트워크의 일반화 능력을 충분히 활용하지 않으며, 에이전트가 OOD 상태-동작을 무조건 억제함으로써, 데이터 범위 바깥의 좋은 선택지까지 제한할 수 있음.
- 본 연구의 제안: 불확실성 기반 모델 프리 Offline RL
- Q-함수 네트워크의 앙상블을 사용해 Q-값 추정의 불확실성을 정량화하고, 데이터 분포 추정이나 샘플링이 필요 없는 불확실성 기반 offline RL 방법을 제안함.
- 온라인 RL에서 사용되는 clipped Q-learning 기법을 불확실성 기반 패널티로 활용하여, Q-값의 신뢰도를 바탕으로 OOD 상태-동작 쌍에 대한 학습을 조정함.
ensemble을 통한 Q-값 추정의 uncertainty 정량화
- Q-function 추정: Q-function은 강화학습에서 state-action pair에 대한 보상의 기대값을 추정하는 함수
- uncertainty: Q-value를 추정할 때 얼마나 신뢰할 수 있는지를 나타내는 개념. 강화학습 학습 시에 OOD state-action에 대해서는 Q-value의 신뢰도가 낮아질 수 있다. 이때, 잘못된 Q-value를 과대 평가하는 외삽 오류가 발생할 수 있다. 즉, 불확실헝이 높은 Q-value는 정확하지 않는 추정일 가능성이 크다. (uncertainty가 높음)
- ensemble을 통한 Q-값 추정의 uncertainty 정량화
- ensemble: 여러 개의 Q-function network를 동시에 훈련하는 기법. 각각의 network는 동일한 입력(state-action pair)에 대해 약간 다른 Q-value를 추정하게 된다.
- uncertainty 추정: 다수의 네트워크가 동일한 state-action pair에 대해서 추정한 Q-value가 비슷하다면, 해당 Q-value에 대해 높은 신뢰성을 가질 수 있다. 반면, 네트워크 간의 추정 Q-value가 크게 차이난다 불확실성이 높다고 할 수 있다. 즉, 다수의 네트워크가 내는 결과의 variance를 통해 불확실성을 정량화 할 수 있다.
→ 단일 Q-function network가 낼 수 있는 과대평가를 방지하고 불확실성이 큰 영역에서는 정책이 너무 낙관적인 결정을 하지 않도록 도와준다.
- 실험 및 성능 개선
- 실험 결과, 앙상블 크기를 늘리는 것만으로도 여러 offline RL 작업에서 최첨단 성능을 달성할 수 있었음.
- 이를 더욱 실용적으로 만들기 위해, 앙상블 다양화 목표를 도입하여 앙상블 네트워크의 수를 줄이면서도 성능을 유지함.
- 제안된 방법은 D4RL 벤치마크에서 다양한 환경 및 데이터셋에서 기존 최첨단 방법들을 크게 능가함.
ensemble 다양화
의미: 앙상블에 속한 각 네트워크가 서로 충분히 다르게 학습되도록 유도하는 것.
- 다양성 유지
- 각 네트워크가 비슷한 Q-value를 추정하게 되면, 중복된 정보만 제공하게 되어서 앙상블의 효과가 줄어든다.
- 다양화를 하면 각 앙상블 네트워크가 서로 차별화된 Q-value를 추정하도록 유도함으로써, 적은 수의 네트워크로도 다양한 의견을 낼 수 있도록 한다.
- 다양화하는 방법?
- 앙상블 네트워크 간의 상관관계를 줄이는 것이다. 즉, 네트워크들이 비슷한 Q-value을 추정하지 않도록 서로 다른 경로로 학습하게 만든다.
- 이를 위해, 각 네트워크가 특정 state-action pair에서 상이한 학습 목표를 가지게 한다. 예를 들어, 일부 네트워크는 특정 범위 내의 동작을 더 강조해서 학습하고, 다른 네트워크는 다른 범위를 더 강조한다.
(2021) [TD3BC] A minimalist approach to offline reinforcement learning
https://arxiv.org/abs/2106.06860
Scott Fujimoto, Shixiang Shane Gu
Abstract
- Offline RL은 고정된 데이터셋에서 학습하는 과제를 정의함.
- OOD 동작에서 발생하는 가치 추정 오류로 인해 대부분의 offline RL 알고리즘은 정책을 데이터셋 내 동작에 제약하거나 정규화함.
- 본 연구는 최소한의 수정만으로 RL 알고리즘을 offline에서 작동하게 할 수 있음을 보여줌.
- 행동 복제 항을 정책 업데이트에 추가하고 데이터를 정규화하는 방법으로 최첨단 성능에 도달하면서도 실행 시간을 절반 이상 줄임.
Introduction
- 강화학습(RL)과 온라인 학습의 전통적 역할
- RL은 에이전트가 환경과 상호작용하며 학습하는 온라인 학습 패러다임에 속한다.
- 에이전트는 시행착오 과정을 통해 환경에서의 행동이 미래 보상에 미치는 영향을 학습한다.
- 그러나, 온라인 학습은 실세계 응용에서 비현실적일 수 있다. 예를 들어, 데이터 수집이 비용이 많이 들거나 또는 위험할 수 있기 때문이다.
- Offline RL의 중요성
- Offline RL(과거에는 batch RL)은 고정된 데이터셋에서 학습을 진행하며, 에이전트가 환경과 직접 상호작용할 필요 없이 미리 수집된 데이터를 통해 학습할 수 있다.
- 이는 데이터 수집이 어렵고 위험한 실제 환경에서 유용하며, 인간 전문가나 기존 데이터를 안전하게 활용할 수 있다.
- 미리 기록된 데이터를 활용함으로써, 훈련되지 않은 RL 에이전트의 탐색으로 인한 위험을 회피할 수 있다.
- Offline RL의 주요 과제: 외삽 오류(Extrapolation Error)
- Offline RL에서 중요한 문제는 데이터셋에 포함되지 않은 상태-동작 쌍에 대한 가치(Q-값)를 잘못 평가하는 외삽 오류이다.
- 기존의 off-policy RL 알고리즘은 offline 설정에서 적용 가능하지만, 외삽 오류로 인해 성능이 크게 저하된다.
- 이는 정책 평가에서 잘못된 가치 추정이 발생하여 잘못된 동작을 학습하게 만들고, 에이전트가 OOD 동작(Out-of-Distribution)을 과대평가하게 되어 정책 개선에 문제가 발생한다.
- Fujimoto et al., 2019b는 이러한 문제를 지적하며, 학습된 정책이 데이터 생성 과정(행동 정책)과 가깝게 유지되어야 한다고 주장한다.
- Offline RL에서 정책 제약 기법들
- 외삽 오류를 해결하기 위한 방법으로 학습된 정책이 데이터 생성 과정에 가깝게 유지되도록 하는 여러 접근들이 제안되었다.
- 이러한 접근 방식은 각각 batch-constrained [Fujimoto et al., 2019b], KL-control [Jaques et al., 2019], behavior-regularized [Wu et al., 2019], policy constraint [Levine et al., 2020] 등의 이름으로 불린다.
- 이러한 방법들의 공통적인 아이디어는, 학습된 정책이 행동 정책(behavior policy)에 너무 멀어지지 않도록 정규화나 제약을 가하는 것이다.
- 기존 알고리즘의 복잡성 문제
- 많은 offline RL 알고리즘은 성능을 높이기 위해 다양한 보조 구성 요소를 도입한다.
- 예를 들어, 생성 모델을 추가하거나 새로운 하이퍼파라미터를 도입하여 정책을 조정하는 등 기존의 온라인 RL 알고리즘을 상당히 수정하게 된다.
- 이러한 추가적인 구성 요소들은 재현 가능성을 떨어뜨리고, 튜닝 과정이 복잡해질 뿐만 아니라, 실행 시간도 크게 늘어난다.
- 또한, 성능 향상의 원인을 명확히 분석하거나 다른 알고리즘에 기법을 적용하는 데 어려움이 발생한다.
- 단순한 해결책을 탐구해야 할 필요성
- 이러한 복잡한 알고리즘적 접근은 offline RL에서의 실제적인 문제 해결을 어렵게 만들 수 있다.
- 기존의 복잡한 방법론을 단순화하여, 최소한의 변경만으로 offline RL이 가능하다면, 이는 큰 실용적 가치를 가진다.
- TD3 알고리즘을 활용한 최소주의적 접근 π=argmaxπE(s,a)∼D[λQ(s,π(s))−(π(s)−a)2]
- 본 논문에서는 기존 TD3 알고리즘 [Fujimoto et al., 2018]의 정책 업데이트 단계에 단순히 행동 복제(behavior cloning) 항을 추가함으로써 성능을 크게 향상시킬 수 있음을 제시한다.
- 구체적으로, TD3의 정책 업데이트는 기존의 결정론적 정책 기울기(deterministic policy gradient) [Silver et al., 2014]을 따르지만, 여기에 정규화 항을 추가한다:
- 여기서 λ는 정규화의 강도를 제어하는 단일 하이퍼파라미터로, 복잡한 조정 없이도 성능을 크게 향상시킬 수 있다.
- 데이터 정규화의 중요성
- 또한, 데이터셋에서 상태를 정규화하여 평균을 0, 표준편차를 1로 조정하는 것이 학습된 정책의 안정성을 높인다는 것을 발견했다.
- 이 정규화 과정은 정책의 안정적인 학습을 돕는 간단하지만 중요한 과정이다.
- 간단한 변화로 성능 향상
- 본 연구에서 제안한 TD3+BC는 단순한 코드 수정만으로 구현이 가능하며, 기존 offline RL 알고리즘들과 비슷한 수준의 성능을 달성한다.
- D4RL 벤치마크의 연속 제어 작업에서 실험한 결과, 제안된 알고리즘은 기존의 복잡한 방법들에 비해 더 적은 계산 비용으로 비슷한 성능을 달성하였다.
- 특히, 실행 시간이 절반 이상 감소하면서도 성능은 그대로 유지되는 점에서 단순한 방법이 복잡한 접근법에 비해 덜 탐구되었음을 보여준다.
(2022) [MCQ] Mildly conservative q-learning for offline reinforcement learning
https://arxiv.org/abs/2206.04745
Jiafei Lyu, Xiaoteng Ma, Xiu Li, Zongqing Lu
Abstract
- Offline RL은 고정된 데이터셋에서 학습하며, OOD 동작이 과대평가되지 않도록 가치 함수는 보수적이어야 함.
- 기존 방식들은 보수성을 유지하려다 일반화를 억제하며 성능을 제한함.
- MCQ(Mildly Conservative Q-learning)는 OOD 동작을 적절한 의사 Q 값을 통해 적극적으로 학습시킴.
- 이론적으로 MCQ는 행동 정책보다 성능이 나쁘지 않으며, OOD 동작에 대한 과대평가 오류가 발생하지 않도록 보장됨.
- D4RL 벤치마크 실험에서 MCQ는 탁월한 성능을 보였으며, 특히 offline에서 online으로 전환할 때 뛰어난 일반화 능력을 입증함.
Introduction
- 온라인 RL의 한계
- 온라인 RL은 에이전트가 환경과 지속적으로 상호작용하면서 학습해야 하는데, 이는 실세계 응용에서 비현실적이거나 불가능할 수 있음.
- 데이터 수집 과정은 종종 비용이 크고, 어려우며, 심지어 위험할 수 있음.
- 예: 자율주행, 로봇 제어, 헬스케어와 같은 실제 환경에서의 상호작용은 높은 위험을 초래할 수 있음.
- Offline RL의 등장
- Offline RL은 고정된 정적 데이터셋을 사용하여 학습을 진행하고, 환경과의 상호작용 없이 문제를 해결함으로써 위의 문제를 해결하고자 함 [36].
- 미리 수집된 데이터셋을 사용하기 때문에 추가적인 상호작용이 없으며, 리스크를 크게 줄임.
- Offline RL의 주요 도전 과제: 분포 차이 문제
- Offline RL에서 가장 큰 도전은 학습된 정책과 행동 정책 간의 상태-동작 방문 빈도 분포의 차이임.
- 학습된 정책은 새로운 동작을 탐색할 수 있지만, 이러한 Out-of-Distribution (OOD) 동작에 대한 평가에서는 외삽 오류(extrapolation error)가 발생할 수 있음.
- 이러한 오류는 부트스트래핑을 통해 더욱 악화되어 심각한 Q-값 과대평가 오류로 이어질 수 있음 [14, 34].
- Offline RL에서 가장 큰 도전은 학습된 정책과 행동 정책 간의 상태-동작 방문 빈도 분포의 차이임.
- 기존 보수적 방법의 한계
- 기존의 Offline RL 방법들은 보수성을 유지하기 위해 몇 가지 전략을 사용함:
- 학습된 정책이 행동 정책에 가깝도록 정규화 [14, 58, 34, 13, 57].
- OOD 동작의 Q-값을 과도하게 비관적으로 패널티화 [35, 33, 59].
- OOD 샘플을 아예 사용하지 않고 학습 [56, 8, 62, 32, 40].
- 하지만 이러한 방식들은 과도한 보수성으로 인해 일반화 능력을 제한하고, 성능이 저하되는 문제가 발생함.
- 특히, 낙관적 가치 추정이 필요한 상황에서도 정책이 과도하게 비관적으로 학습됨.
- 기존의 Offline RL 방법들은 보수성을 유지하기 위해 몇 가지 전략을 사용함:
- 일반화와 성능 향상을 위한 필요성
- 신경망은 연속적인 state-action 공간에서 학습된 데이터를 인접한 보지 못한 상태와 동작으로 일반화해야 함.
- 예를 들어, 비최적 경로를 결합해 최적 경로를 생성할 수 있도록 하는 능력이 중요함.
- 그러나 기존의 보수성 유지 기법은 이러한 일반화를 저해하고, 에이전트의 성능 향상을 막음.
- 정책 정규화는 수집된 데이터의 질이 낮을 경우 신뢰도가 떨어지며, 가치 패널티 방식은 데이터셋 내와 OOD 영역 모두에서 불필요하게 비관적이 됨.
- 신경망은 연속적인 state-action 공간에서 학습된 데이터를 인접한 보지 못한 상태와 동작으로 일반화해야 함.
- Mildly Conservative Q-learning (MCQ)의 제안
- 우리는 필요 최소한의 보수성을 유지하는 새로운 방식인 **Mildly Conservative Q-learning (MCQ)**을 제안함.
- MCQ는 OOD 동작을 적절한 의사 Q 값을 할당해 적극적으로 학습하며, 일반화를 해치지 않으면서 보수성을 유지함.
- OOD 동작의 Q 값을 약간 낙관적으로 설정하여 성능 향상과 보수성 간의 균형을 맞춤.
- 이로 인해 Q(s, a^ood) < max_{a∈Support(µ)} Q(s, a) 조건을 충족시키면서 OOD 동작에 대한 잘못된 과대평가가 발생하지 않도록 보장함.
- 우리는 필요 최소한의 보수성을 유지하는 새로운 방식인 **Mildly Conservative Q-learning (MCQ)**을 제안함.
- Mildly Conservative Bellman (MCB) 연산자
- MCB 연산자는 OOD 동작에 대해 더 나은 가치 추정을 제공하고, 이를 적극적으로 학습하며, 성능을 개선하는 새로운 기법임.
- 이론적으로 MCB 연산자는 학습된 정책이 행동 정책보다 성능이 나쁘지 않도록 하며, 기존 보수성 기법보다 더 엄격한 하한을 보장함.
엄격한 하한을 둔다 = 정책의 성능 평가에서, 학습된 Q-값이 지나치게 낙관적이지 않도록 보수적인 값을 유지하는 것을 의미
- 정책이 데이터셋에 존재하는 동작에 대해 학습된 Q-값을 사용할 때는 일반적인 Bellman 백업을 수행하지만, OOD 동작에 대해서는 신뢰할 수 없는 값을 가지지 않도록 고의적으로 낮은 Q-값을 할당한다.
- 이를 통해 OOD 동작에 대해 낙관적일 수 없는 Q-값을 보장하면서, OOD 동작이 학습된 정책에서 선택되지 않도록 한다.
MCB 연산자의 OOD 동작에 대한 가치 추정 메커니즘
- OOD 동작을 적극적으로 학습: MCB 연산자는 OOD 동작을 단순히 무시하지 않고, 해당 동작들에 적절한 Q-값을 할당한다. 이를 통해 OOD 동작을 학습 과정에서 고려하게 된다.
- 구체적으로, OOD 동작에 대해서는 maxa'∼Support(µ(·|s))Q(s, a')와 같은 상한을 두고, 이를 초과하지 않도록 한다. 이 방식은 학습된 정책이 최적 행동 정책을 추정하면서도 과대평가하지 않도록 보장한다.
- T1과 T2의 이중 백업: MCB 연산자는 OOD 동작을 확인하고, T1과 T2 연산을 통해 OOD 동작에 대해 낮은 Q-값을 할당한다.
- T1은 정책이 행동 정책(behavior policy)에서 지원(support)되는 영역 안에 있는지 확인하는 역할을 한다.
- 지원 내 동작: 정책 동작이 행동 정책 지원 내에 있다면 Q(s, a) 반환
- 지원 외 동작: OOD 동작으로 간주하고, 해당 동작에 대해 가상의 pseudo target value을 할당
- T2는 이를 기반으로 OOD 동작의 Q-값을 평가하는 단계이다. 이 과정은 OOD 동작이 학습에 포함되면서도 과대평가되지 않도록 보장한다.
- 지원 내 동작: 표준 Bellman 연산을 사용해서 Q값을 업데이트
- 지원 외 동작: OOD 동작에 대해서는 r(s, a) + γEs′ [Q(s, a)] 값을 사용하여 보수적인 값을 할당
- T1은 정책이 행동 정책(behavior policy)에서 지원(support)되는 영역 안에 있는지 확인하는 역할을 한다.
- δ 값을 통한 보수성 조정: OOD 동작에 대해 설정된 Q-값에서 δ(델타) 값을 빼서 이 Q-값을 약간 낮게 설정한다. 이로 인해 OOD 동작이 정책에서 선택되지 않도록 조정하며, 잘못된 과대평가를 방지한다.
- MCQ의 적용 및 성능
- 조건부 변동 자동 인코더(CVAE)로 행동 정책을 추정하고, Soft Actor-Critic (SAC) 알고리즘과 결합한 MCQ는 D4RL MuJoCo 이동 작업에서 기존 방법들을 대부분 능가하는 성능을 보였음.
- 특히, 비전문가(non-expert) 데이터셋에서 뛰어난 성능을 발휘.
- 또한, offline에서 online으로 전환할 때도 우수한 일반화 능력을 보여, 온건한 비관주의가 offline 학습에 중요함을 입증.
- 조건부 변동 자동 인코더(CVAE)로 행동 정책을 추정하고, Soft Actor-Critic (SAC) 알고리즘과 결합한 MCQ는 D4RL MuJoCo 이동 작업에서 기존 방법들을 대부분 능가하는 성능을 보였음.
(2023) [PRDC] Policy Regularization with Dataset Constraint for Offline Reinforcement Learning
https://arxiv.org/abs/2306.06569
Yuhang Ran, Yi-Chen Li, Fuxiang Zhang, Zongzhang Zhang, Yang Yu
Abstract
- Offline RL은 고정된 데이터셋에서 학습하는데, 기존 방법들은 학습된 정책을 행동 정책의 분포나 지원으로 제약함.
- 이러한 제약은 지나치게 보수적이어서, 특히 행동 정책이 비최적일 때 학습된 정책의 성능을 제한할 수 있음.
- PRDC(Policy Regularization with Dataset Constraint)는 상태-동작 쌍에서 가장 가까운 이웃을 찾아, 정책을 더 나은 동작으로 가이드함.
- PRDC는 부드러운 제약을 제공하면서도 OOD 동작으로부터 충분한 보수성을 유지함.
- PRDC는 가치 과대평가 문제를 완화하고, 기존 방법들과 비교하여 최첨단 성능을 달성함.
Introduction
- 온라인 RL의 성공과 한계
- 온라인 RL은 게임(Silver et al., 2017), 로봇공학(Li et al., 2021), 추천 시스템(Chen et al., 2018) 등에서 주목할 만한 성공을 이루었다.
- 하지만, 온라인 RL은 지속적인 환경과의 상호작용을 요구하며, 이는 비용이 크거나, 안전 문제가 있어 실제 응용에서는 어려움을 야기할 수 있다.
- 온라인에서 최적의 정책을 학습하려면 에이전트가 시행착오 방식으로 환경과 수백만 번 이상 상호작용해야 한다(Sutton & Barto, 2018).
- 이는 데이터 수집 비용이 매우 크거나 위험한 상황에서는 실현하기 어려워, 실제 응용에서 제한된다.
- Offline RL의 장점과 최근 관심
- Offline RL은 미리 수집된 고정된 데이터셋을 기반으로 학습하며, 훈련 중 추가 상호작용이 필요 없다.
- 이를 통해 안전하지 않은 환경이나, 데이터 수집 비용이 큰 응용에서 RL을 적용할 수 있는 가능성을 제공한다.
- Offline RL은 특히 기존 데이터셋을 강력한 의사결정 엔진으로 전환할 수 있다는 잠재력 덕분에 최근 몇 년간 많은 관심을 받아왔다(Levine et al., 2020).
- 이는 RL의 데이터 기반 접근을 확장하는 중요한 방향성을 제시한다.
- Offline RL의 주요 문제: OOD 동작에 대한 가치 과대평가
- Offline RL에서의 근본적인 문제는, Out-of-Distribution (OOD) 동작에 대해 가치(Q-값)가 과대평가되는 경향이 있다는 것이다(2.3절 참조).
- OOD 동작은 행동 정책에 의해 자주 수행되지 않은 동작으로, 이런 동작에 대한 신뢰할 수 있는 평가 데이터를 충분히 확보하기 어렵다.
- 에이전트는 OOD 동작에 대해 잘못된 가치 추정을 할 수 있으며, 이는 정책 개선에 부정적인 영향을 미친다. 에이전트가 잘못된 동작을 선호하게 되어 성능이 크게 저하된다.
- OOD 동작을 다루는 기존의 두 가지 주요 접근 방식
- 비관적 가치 기반 접근법
- OOD 동작의 가치를 과소평가하거나, 보수적인 가치 함수를 학습하여 에이전트가 OOD 동작을 선택하지 않도록 유도한다(Kumar et al., 2020; Yu et al., 2021).
- 이 접근법은 에이전트가 낙관적인 동작 선택을 억제하고, 학습된 정책이 OOD 동작을 피할 수 있도록 한다.
- 정규화된 정책 기반 접근법
- 정책을 데이터셋에서 자주 나타나지 않는 상태-동작을 피하도록 정규화하거나 제약을 가한다(Fujimoto et al., 2019; Nair et al., 2020).
- 이 접근은 주어진 데이터셋에 충분히 포함된 동작만을 선택하도록 정책을 제약하며, OOD 동작을 탐색하지 않게 한다.
- 비관적 가치 기반 접근법
- 정책 정규화의 한계
- 기존의 정책 정규화 접근법은 학습된 정책을 행동 정책의 분포(Wu et al., 2019) 또는 행동 정책의 지원(Kumar et al., 2019)으로 제약한다.
- 이러한 방법은 특정 상태에서 정책이 행동 정책의 동작만을 선택하도록 강요하여, 지나치게 보수적일 수 있다.
- 특히, 행동 정책이 비최적일 때, 정책이 비효율적인 행동을 선택하게 되어 성능이 제한된다.
- 또한, 주어진 상태에서 최적의 동작이 없을 때도, 제한된 동작 선택지만으로 학습된 정책을 제약하는 것은 성능을 저하시킬 수 있다.
- 새로운 정책 정규화 접근의 필요성
- 특정 상태에서 최적의 동작이 주어진 데이터셋 내에 없을 경우, 에이전트가 더 나은 동작을 선택할 수 있는 유연성이 필요하다.
- 주어진 상태에 국한된 동작이 아닌, 데이터셋 전체에서 더 나은 동작을 선택하도록 정책을 가이드할 수 있는 방법을 제시할 필요가 있다.
- 이러한 필요성은 더 부드러운 정책 정규화 기법의 개발로 이어진다.
- PRDC(Policy Regularization with Dataset Constraint)의 제안
- 본 연구에서는 주어진 상태에서 학습된 정책이 가장 가까운 상태-동작 이웃(nearest neighbor)을 기반으로 동작을 선택하는 새로운 방법인 PRDC를 제안한다.
- PRDC는 주어진 상태에서 데이터를 탐색하여, 해당 상태와 가장 가까운 상태-동작 쌍을 찾아 이를 정책의 제약으로 사용한다.
- 이는 기존의 분포 또는 지원 기반 제약과 달리, 데이터셋 전체를 활용하여 더 나은 동작을 선택할 수 있도록 가이드하는 방법이다.
- PRDC는 주어진 상태에서 존재하지 않는 더 나은 동작을 허용하면서도, 충분한 보수성을 유지하여 OOD 동작의 잘못된 선택을 방지한다.
- PRDC의 성능 및 구현
- PRDC는 TD3(Fujimoto et al., 2018)와 같은 Actor-Critic 알고리즘에 결합할 수 있으며, 이를 기반으로 고효율적 구현을 제공한다(3절 참조).
- 실험 결과, PRDC는 기존의 방법들보다 가치 과대평가 문제를 효과적으로 완화하면서도, 성능 격차를 최소화할 수 있음을 입증했다.
- 특히, Gym 및 AntMaze 작업에서 PRDC는 기존 알고리즘들과 비교하여 최첨단 성능을 달성했다(5절 참조).
'ML & DL > RL' 카테고리의 다른 글
| [RL] offline RL constraint 유형 정리 (0) | 2024.09.24 |
|---|---|
| [RL paper] Deep reinforcement learning in transportation research: A review (1) | 2024.09.05 |
| [RL] Offline Reinforcement Learning: From Algorithms to Practical Challenges 강의 해석 (2) (0) | 2024.08.12 |
| [RL] Offline Reinforcement Learning: From Algorithms to Practical Challenges 강의 해석 (1) (0) | 2024.08.11 |
| [RL] Actor-Critic 알고리즘 간단하게 개념 정리 (0) | 2024.08.05 |
(2018) [BCQ] Off-Policy Deep Reinforcement Learning without Exploration
https://arxiv.org/abs/1812.02900
Scott Fujimoto, David Meger, Doina Precup
Abstract
- 많은 강화학습 응용은 고정된 데이터 배치에서 학습해야 하며, 추가적인 데이터 수집이 불가능함.
- 표준 Off-policy 알고리즘(DQN, DDPG)은 현재 정책과 상관된 데이터가 없으면 학습할 수 없으며, 고정된 배치 설정에서 효과적이지 않음.
- Batch-Constrained Reinforcement Learning을 제안하며, 에이전트가 행동 공간을 제한하여 주어진 데이터와 On-policy에 가깝게 행동하도록 유도함.
- BCQ 알고리즘은 연속 제어 문제에서 고정된 배치 데이터를 사용해 효과적으로 학습할 수 있는 첫 번째 알고리즘임을 입증함.
Introduction
- 배치 강화학습의 필요성
- 배치 강화학습은 고정된 데이터셋에서 학습하는 작업으로, 환경과 추가 상호작용 없이 학습함.
- 이는 데이터 수집 절차가 비용이 많이 들거나 위험하거나 시간이 많이 소요될 때 필수적인 방법임.
- 예를 들어, 로봇 제어나 의료 응용에서 데이터 수집이 비용 및 위험성이 크므로, 이러한 환경에서는 배치 강화학습이 필요함.
- Off-policy 배치 강화학습의 실질적 이점
- 배치 강화학습을 통해, 데이터 수집을 2차 제어 프로세스 (예: 인간 운영자, 모니터링된 프로그램)로 안전하게 수행할 수 있음.
- 이는 더 효율적이며 안전한 데이터 수집 절차를 가능하게 하며, 위험한 환경에서의 실시간 상호작용을 최소화함.
- 모방 학습의 한계
- 모방 학습은 행동 정책의 품질에 대한 강력한 가정이 필요하며, 이는 비최적 경로에 노출되면 실패할 수 있음.
- 또한 모방 학습은 종종 환경과의 추가 상호작용이 필요하여, 이를 보완해야 하는 경우가 많음.
- 반면, 배치 강화학습은 고정된 데이터셋에서 학습할 수 있으며, 데이터 품질에 제한을 두지 않음.
- 기존 Off-policy 알고리즘의 문제점
- 현대 Off-policy 강화학습 알고리즘은 일반적으로 데이터를 경험 재생 버퍼(replay buffer)에 저장한 후, 더 많은 데이터를 수집하기 전에 그 데이터를 사용하여 에이전트를 학습시키는 Growing Batch Learning 방식에 의존함.
- 하지만 고정된 배치 데이터를 사용할 때, 이 알고리즘들이 실패할 수 있음.
- 특히, 현재 정책과 연관되지 않은 데이터를 사용할 경우, 학습 성능이 크게 떨어짐.
- 외삽 오류의 원인 및 영향
- 외삽 오류(extrapolation error)는 보지 못한 상태-동작 쌍에 대해 Q-함수가 비현실적인 값을 예측하는 현상임.
- 이는 정책이 유도하는 데이터 분포와 배치 데이터에 포함된 분포 간의 불일치로 인해 발생함.
- 외삽 오류는 정책이 배치에 포함되지 않은 동작을 선택할 때, 올바른 가치 함수를 학습할 수 없게 만듦.
- Batch-Constrained Reinforcement Learning의 도입
- 외삽 오류를 해결하기 위해, 우리는 Batch-Constrained Reinforcement Learning을 제안함.
- 이 방법은 에이전트가 보상을 최대화하면서, 정책의 상태-동작 방문과 배치에 포함된 상태-동작 쌍 간의 불일치를 최소화하도록 학습함.
- BCQ 알고리즘의 원리
- Batch-Constrained deep Q-learning (BCQ) 알고리즘은 상태-조건부 생성 모델을 사용하여 이전에 본 동작만을 생성함.
- 이 생성 모델은 Q-네트워크와 결합되어, 배치 데이터와 유사한 가장 높은 가치의 동작을 선택함.
- BCQ는 환경과 상호작용 없이도 성공적으로 학습할 수 있도록 설계되었으며, 외삽 오류를 효과적으로 고려함.
- 실험 결과
- MuJoCo 환경에서 고차원 연속 행동 공간에서 평가한 결과, BCQ는 외삽 오류가 큰 문제로 나타나는 배치 강화학습 작업에서 우수한 성능을 보임.
- BCQ는 순수 전문가 데모뿐만 아니라 비최적 데이터가 포함된 고정 배치에서도 학습할 수 있음.
(2020) [CQL] Conservative Q-Learning for Offline Reinforcement Learning
https://arxiv.org/abs/2006.04779
Aviral Kumar, Aurick Zhou, George Tucker, Sergey Levine
Abstract
- Offline RL 알고리즘은 정적 데이터셋에서 상호작용 없이 효과적인 정책을 학습하는 것을 목표로 함.
- Offline RL에서 분포적 차이로 인해 표준 Off-policy RL 방법은 가치의 과대평가로 실패할 수 있음.
- Conservative Q-learning(CQL)은 보수적인 Q-함수를 학습하여 정책의 기대값이 실제 값보다 하한을 두도록 설계됨.
- CQL은 Bellman 오차에 Q-값 정규화를 추가하여 구현되며, 기존 deep Q-learning 및 actor-critic 방법과 호환 가능함.
- CQL은 이론적으로 정책의 값에 하한을 제공하며, 다양한 실험에서 기존 Offline RL 방법보다 2~5배 더 높은 최종 보상을 달성함.
Introduction
- RL의 최근 발전과 Offline RL의 필요성
- RL은 로봇공학, 전략 게임, 추천 시스템 등에서 유망한 성과를 거두었으나, 실제 환경에서의 상호작용은 비용이 크고 위험할 수 있음.
- Offline RL은 정적 데이터셋에서 학습하여 상호작용 없이 정책을 최적화할 수 있는 방법을 제시함.
- 그러나 정책을 수집한 데이터와 학습된 정책 간의 분포 차이로 인해 성능 저하가 발생함.
- 기존 Off-policy RL 알고리즘의 한계
- Offline 환경에서 기존 Off-policy RL 알고리즘을 직접 사용하면 분포 외 행동으로 인해 외삽 오류가 발생함.
- 이러한 오류는 과대평가된 Q-함수로 이어져 잘못된 정책 평가를 초래함.
- CQL의 제안과 핵심 아이디어
- Conservative Q-learning(CQL)은 보수적인 Q-함수를 학습하여 정책의 기대값이 실제 값보다 하한을 두도록 설계됨.
- 정책 하에서 Q-함수의 기대값에만 하한을 두는 방식으로, 점별(point-wise) 하한보다 효율적인 정책 평가를 가능하게 함.
- 상태-동작 쌍에 대한 최소화와 데이터 분포에 대한 최대화를 결합하여 Q-값을 보수적으로 추정함.
- Conservative Q-learning(CQL)은 보수적인 Q-함수를 학습하여 정책의 기대값이 실제 값보다 하한을 두도록 설계됨.
- CQL의 장점 및 실험 결과
- CQL은 복잡한 데이터셋과 고차원 시각 입력을 다룰 때 기존 방법보다 2~5배 더 높은 성능을 보임.
- 단순한 행동 복제를 능가하는 성능을 제공하는 유일한 방법임.
- CQL은 기존 온라인 RL 알고리즘에 간단하게 통합할 수 있으며, 적은 양의 코드로 구현 가능함.
(2020) [CRR] Critic Regularized Regression
https://arxiv.org/abs/2006.15134
Ziyu Wang, Alexander Novikov, Konrad Zolna, Jost Tobias Springenberg, Scott Reed, Bobak Shahriari, Noah Siegel, Josh Merel, Caglar Gulcehre, Nicolas Heess, Nando de Freitas
Abstract
- Offline RL은 사전 기록된 데이터셋을 사용하여 정책 최적화를 가능하게 하며, 데이터 수집 비용과 안전성 문제를 해결한다.
- 대부분의 off-policy 알고리즘은 고정된 데이터셋에서 학습할 때 성능이 좋지 않다.
- 본 논문에서는 critic-regularized regression(CRR) 기법을 사용한 새로운 offline RL 알고리즘을 제안한다.
- CRR은 고차원 상태 및 행동 공간에서도 확장 가능하며, 다양한 벤치마크에서 다른 최신 알고리즘보다 더 우수한 성능을 보여준다.
Introduction
- Deep RL은 여러 도전적인 도메인에서 성공을 거두었으나, 실세계 의사결정에 사용된 사례는 드물다.
- 온라인 RL은 비용, 안전성, 윤리적 문제로 인해 실세계에서 실행하기 어려운 경우가 많다.
- 많은 도메인에서 대규모의 과거 데이터가 존재하며, 이를 활용한 offline RL에 대한 관심이 커지고 있다.
- RL에서 탐색과 경험 학습을 분리하여 고정된 경험으로부터 학습할 경우 알고리즘 평가 및 비교가 용이해진다.
- 기존 off-policy RL 알고리즘은 고정된 데이터에서 실패하는 경우가 많으며, 지나치게 낙관적인 Q-추정과 데이터 외삽이 주요 원인이다.
- CRR은 value-filtering된 회귀 형태로 정책 최적화를 수행하며, actor-critic 방법에 최소한의 변경만 필요하다.
- 실험 결과, CRR은 고차원 상태 및 행동 공간에서도 우수한 성능을 보였다.
- 격자(grid): 에이전트(로봇 등)가 여러 방향으로 움직일 수 있는 환경. 에이전트는 왼쪽 아래에서 시작해(시작점, 파란 다이아몬드) 보상이 있는 상자를 찾아가야 한다.
- 화살표(초록색/빨간색): 화살표는 에이전트가 각 상태에서 취할 수 있는 행동을 나타낸다. 초록색 화살표는 좋은 행동(현재 정책보다 나은 행동)을 의미하고, 빨간색 화살표는 나쁜 행동(현재 정책보다 나쁜 행동)을 의미한다.
- 검정색 화살표: 현재 학습 중인 정책이 각 상태에서 제안하는 행동이다.
CRR 알고리즘 동작 방식
- 현재 정책의 행동(검정 화살표)과 배치에서 나온 행동(빨간색 또는 초록색 화살표)을 비교한다.
- Q값 비교: 각 상태에서 특정 행동의 가치(Q값)를 계산하여, 배치에서 나온 행동(과거 행동)이 현재 정책의 행동보다 더 나은지(Q(st, at) ≥ Q(st, π(st)))를 평가한다.
- 만약 과거 행동이 더 좋다면(초록색 화살표), 그 행동을 정책 학습에 사용한다.
- 만약 과거 행동이 더 나쁘다면(빨간색 화살표), 그 행동은 무시한다.
- 이 과정에서 나쁜 행동(빨간색 화살표)을 걸러내고 좋은 행동(초록색 화살표)만 학습에 반영하여 정책을 개선해나간다.
(2020) [PLAS] Latent Action Space for Offline Reinforcement Learning
https://arxiv.org/abs/2011.07213
Wenxuan Zhou, Sujay Bajracharya, David Held
Abstract
- Offline Reinforcement Learning의 목표는 추가적인 상호작용 없이 고정된 데이터셋에서 정책을 학습하는 것임.
- 기존의 Off-policy 알고리즘은 데이터셋 외부 동작으로 인한 외삽 오류로 인해 정적 데이터셋에서 성능이 제한적임.
- PLAS(Policy in the Latent Action Space)는 명시적인 제약 없이 정책을 데이터셋의 지원 내에서 학습하는 간단한 방법을 제안함.
- PLAS는 시뮬레이션 연속 제어 벤치마크 및 실제 로봇 변형 객체 조작 작업에서 기존 방법보다 일관되게 높은 성능을 제공함.
Introduction
- 강화학습(RL)의 성공과 한계
- 강화학습(RL)은 시뮬레이션에서 로봇 작업과 같은 여러 분야에서 큰 성과를 거두었음 [1, 2].
- 그러나 실제 세계, 특히 실제 로봇에 RL을 적용하는 데에는 여전히 제한적임.
- 주요 도전 과제: RL은 환경과의 대규모 온라인 상호작용을 요구하며, 보통 수백만 번의 타임 스텝이 필요함.
- Offline Reinforcement Learning (Offline RL)의 등장
- Offline RL, 또는 Batch RL,은 정적 데이터셋을 기반으로 정책을 최적화하는 알고리즘을 개발하는 것에 중점을 둠 [3, 4].
- 로봇공학에서의 중요성
- 데이터 수집 과정에서 더 많은 유연성을 제공함.
- 안전성을 고려하거나 더 나은 탐사 방법을 사용할 수 있음 [5].
- 데모(demonstration)를 활용할 수 있음 [6].
- Offline RL이 제공하는 추가적인 이점
- 과거 경험의 재사용: 이전 RL 실험에서 평가 궤적이나 리플레이 버퍼를 재사용할 수 있음.
- 데이터셋 공유: 정적 데이터셋은 커뮤니티 내에서 쉽게 공유될 수 있으며, 데이터셋의 크기가 확장 가능함.
- Off-policy RL의 문제점
- Off-policy RL은 훈련 절차 동안 정책에 의해 능동적으로 수집된 전이(transition)를 저장하는 리플레이 버퍼를 사용함.
- 기존 연구에서는 Off-policy RL 방법이 정적 데이터셋에 직접 적용되지 않는 이유를 지적함
- 데이터셋 외부 동작(out-of-distribution actions)으로 인한 Q-함수의 외삽 오류가 발생함 [7].
- 외삽 오류 문제와 정책 제약의 필요성
- 외삽 오류 방지를 위해서는, 정책이 데이터셋의 지원(support) 내에서 동작을 선택하도록 제한해야 함.
- 하지만 제약이 지나치게 엄격해서는 안 됨
- 과도한 제약은 정책이 행동 복제(behavior cloning)로 퇴화할 수 있음.
- 따라서, 적절한 제약 설계가 중요한 문제로 남아 있음.
- PLAS(Policy in the Latent Action Space) 방법 제안
- 우리는 명시적인 제약을 사용하지 않고, Latent Action Space에서 정책을 훈련하는 간단하면서도 효과적인 방법을 제안함.
- 데이터셋의 행동 정책(behavior policy)을 Conditional Variational Autoencoder (CVAE)로 모델링함
- 핵심 아이디어
- CVAE의 Latent Action Space에서 정책을 학습하고, 이를 디코더로 사용하여 원래의 Action Space에서 동작을 출력함.
- Latent Action Space는 구조적으로 정책을 암묵적으로 제한함.
- 장점
- 제약이 다른 최적화 구성 요소에 영향을 주지 않고 자연스럽게 충족됨.
- 행동 정책 분포의 밀도에 의해 제한받지 않음.
- PLAS의 일반화 성능 및 확장성
- PLAS는 데이터셋 내에서 일반화를 허용하며, 다양한 동작이 포함된 데이터셋에서도 일관되게 좋은 성능을 제공함.
- Q-함수의 일반화 성능이 뛰어날 때에는, 제어된 방식으로 데이터셋 외부 동작을 허용하여 성능을 향상시킴.
- 내부 분포 일반화와 외부 분포 일반화를 명시적으로 분리하여, 사용자가 방법의 일반화 범위에 대해 세부적인 제어를 할 수 있게 함.
- 실험 결과
- 우리는 PLAS를 d4rl 벤치마크 데이터셋의 연속 제어 작업과 실제 로봇 실험에 적용하였으며, 간단함에도 불구하고 이전 방법들보다 우수한 성능을 보였음.
(2021) [EDAC] Uncertainty-based offline reinforcement learning with diversified q-ensemble
https://arxiv.org/abs/2110.01548
Gaon An, Seungyong Moon, Jang-Hyun Kim, Hyun Oh Song
Abstract
- Offline RL은 정적 데이터셋에서 최적의 정책을 찾는 것을 목표로 하지만, OOD 데이터 포인트로 인한 함수 근사 오류로 어려움을 겪음.
- 기존 방법들은 정책이 주어진 데이터에 가깝게 유지되도록 제약 또는 패널티 항을 도입하지만, 행동 정책 추정이나 OOD 샘플링의 어려움이 있음.
- 본 연구는 Q-값의 신뢰도를 고려한 불확실성 기반 offline RL 방법을 제안하며, 데이터 분포 추정이나 샘플링이 필요하지 않음.
- clipped Q-learning을 사용해 OOD 데이터에 대한 예측 불확실성을 패널티화하는 방법을 제시하고, Q-네트워크의 수를 늘려 성능을 향상시킴.
- 제안된 앙상블-다양화된 액터-크리틱 알고리즘은 적은 수의 앙상블 네트워크로도 D4RL 벤치마크에서 최첨단 성능을 달성함.
Introduction
- 심층 강화학습(Deep RL)의 성공 사례
- 로봇공학, 추천 시스템, 전략 게임 등의 분야에서 심층 강화학습(Deep RL)은 주목할 만한 성공을 거둠 [20], [6], [26].
- 이러한 성공은 복잡한 작업에서 심층 신경망의 강력한 학습 능력을 보여줌.
- 능동 학습 절차의 한계
- 대부분의 강화학습(RL) 알고리즘은 능동적 학습 절차를 따름.
- 즉, 훈련 과정에서 에이전트가 환경과 능동적으로 상호작용해야 함.
- 이 시행착오 방식은 실제 응용에서 여러 문제를 일으킬 수 있음.
- 예: 자율주행이나 헬스케어에서는 탐색 중 발생하는 실수나 오류가 에이전트나 환경에 심각한 손상을 초래할 수 있음 [19].
- 대부분의 강화학습(RL) 알고리즘은 능동적 학습 절차를 따름.
- Offline RL의 등장
- Offline RL(배치 RL)은 이미 수집된 데이터셋만을 사용해 정책을 학습함으로써, 추가적인 환경과의 상호작용 없이 문제를 해결하려는 접근임 [2], [11], [19].
- Offline RL은 실제 환경에서의 데이터를 기반으로 RL 문제를 해결할 수 있는 데이터 기반 접근법으로 매우 유망함.
- Offline RL의 알고리즘적 도전
- 최근 연구에 따르면, Offline RL은 몇 가지 새로운 알고리즘적 도전에 직면함 [19].
- 일반적으로 데이터셋이 충분하지 않으면, vanilla RL 알고리즘은 외삽 오류(extrapolation error)로 인해 OOD(Out-of-Distribution) 상태-동작 쌍의 Q-값을 과대평가하여 성능이 크게 저하됨 [15].
- 기존 Offline RL 방법의 접근 방식
- 대부분의 offline RL 방법은 기존 RL 알고리즘에 제약이나 패널티 항을 추가하여 보수적인 학습을 유도함.
- 예를 들어, 일부 연구는 정책이 데이터 수집에 사용된 행동 정책과 가깝게 유지되도록 정규화를 적용함 [11], [15].
- 다른 연구는 OOD 상태-동작 쌍의 Q-값에 패널티를 부여하여, Q-값을 비관적으로 만들도록 함 [16].
- 대부분의 offline RL 방법은 기존 RL 알고리즘에 제약이나 패널티 항을 추가하여 보수적인 학습을 유도함.
- 기존 방법의 한계
- 행동 정책을 추정하거나 OOD 데이터에서 샘플링을 요구하는 기존 방법들은 추정의 어려움과 비효율성을 겪음.
- 또한, 이러한 방법들은 Q-함수 네트워크의 일반화 능력을 충분히 활용하지 않으며, 에이전트가 OOD 상태-동작을 무조건 억제함으로써, 데이터 범위 바깥의 좋은 선택지까지 제한할 수 있음.
- 본 연구의 제안: 불확실성 기반 모델 프리 Offline RL
- Q-함수 네트워크의 앙상블을 사용해 Q-값 추정의 불확실성을 정량화하고, 데이터 분포 추정이나 샘플링이 필요 없는 불확실성 기반 offline RL 방법을 제안함.
- 온라인 RL에서 사용되는 clipped Q-learning 기법을 불확실성 기반 패널티로 활용하여, Q-값의 신뢰도를 바탕으로 OOD 상태-동작 쌍에 대한 학습을 조정함.
ensemble을 통한 Q-값 추정의 uncertainty 정량화
- Q-function 추정: Q-function은 강화학습에서 state-action pair에 대한 보상의 기대값을 추정하는 함수
- uncertainty: Q-value를 추정할 때 얼마나 신뢰할 수 있는지를 나타내는 개념. 강화학습 학습 시에 OOD state-action에 대해서는 Q-value의 신뢰도가 낮아질 수 있다. 이때, 잘못된 Q-value를 과대 평가하는 외삽 오류가 발생할 수 있다. 즉, 불확실헝이 높은 Q-value는 정확하지 않는 추정일 가능성이 크다. (uncertainty가 높음)
- ensemble을 통한 Q-값 추정의 uncertainty 정량화
- ensemble: 여러 개의 Q-function network를 동시에 훈련하는 기법. 각각의 network는 동일한 입력(state-action pair)에 대해 약간 다른 Q-value를 추정하게 된다.
- uncertainty 추정: 다수의 네트워크가 동일한 state-action pair에 대해서 추정한 Q-value가 비슷하다면, 해당 Q-value에 대해 높은 신뢰성을 가질 수 있다. 반면, 네트워크 간의 추정 Q-value가 크게 차이난다 불확실성이 높다고 할 수 있다. 즉, 다수의 네트워크가 내는 결과의 variance를 통해 불확실성을 정량화 할 수 있다.
→ 단일 Q-function network가 낼 수 있는 과대평가를 방지하고 불확실성이 큰 영역에서는 정책이 너무 낙관적인 결정을 하지 않도록 도와준다.
- 실험 및 성능 개선
- 실험 결과, 앙상블 크기를 늘리는 것만으로도 여러 offline RL 작업에서 최첨단 성능을 달성할 수 있었음.
- 이를 더욱 실용적으로 만들기 위해, 앙상블 다양화 목표를 도입하여 앙상블 네트워크의 수를 줄이면서도 성능을 유지함.
- 제안된 방법은 D4RL 벤치마크에서 다양한 환경 및 데이터셋에서 기존 최첨단 방법들을 크게 능가함.
ensemble 다양화
의미: 앙상블에 속한 각 네트워크가 서로 충분히 다르게 학습되도록 유도하는 것.
- 다양성 유지
- 각 네트워크가 비슷한 Q-value를 추정하게 되면, 중복된 정보만 제공하게 되어서 앙상블의 효과가 줄어든다.
- 다양화를 하면 각 앙상블 네트워크가 서로 차별화된 Q-value를 추정하도록 유도함으로써, 적은 수의 네트워크로도 다양한 의견을 낼 수 있도록 한다.
- 다양화하는 방법?
- 앙상블 네트워크 간의 상관관계를 줄이는 것이다. 즉, 네트워크들이 비슷한 Q-value을 추정하지 않도록 서로 다른 경로로 학습하게 만든다.
- 이를 위해, 각 네트워크가 특정 state-action pair에서 상이한 학습 목표를 가지게 한다. 예를 들어, 일부 네트워크는 특정 범위 내의 동작을 더 강조해서 학습하고, 다른 네트워크는 다른 범위를 더 강조한다.
(2021) [TD3BC] A minimalist approach to offline reinforcement learning
https://arxiv.org/abs/2106.06860
Scott Fujimoto, Shixiang Shane Gu
Abstract
- Offline RL은 고정된 데이터셋에서 학습하는 과제를 정의함.
- OOD 동작에서 발생하는 가치 추정 오류로 인해 대부분의 offline RL 알고리즘은 정책을 데이터셋 내 동작에 제약하거나 정규화함.
- 본 연구는 최소한의 수정만으로 RL 알고리즘을 offline에서 작동하게 할 수 있음을 보여줌.
- 행동 복제 항을 정책 업데이트에 추가하고 데이터를 정규화하는 방법으로 최첨단 성능에 도달하면서도 실행 시간을 절반 이상 줄임.
Introduction
- 강화학습(RL)과 온라인 학습의 전통적 역할
- RL은 에이전트가 환경과 상호작용하며 학습하는 온라인 학습 패러다임에 속한다.
- 에이전트는 시행착오 과정을 통해 환경에서의 행동이 미래 보상에 미치는 영향을 학습한다.
- 그러나, 온라인 학습은 실세계 응용에서 비현실적일 수 있다. 예를 들어, 데이터 수집이 비용이 많이 들거나 또는 위험할 수 있기 때문이다.
- Offline RL의 중요성
- Offline RL(과거에는 batch RL)은 고정된 데이터셋에서 학습을 진행하며, 에이전트가 환경과 직접 상호작용할 필요 없이 미리 수집된 데이터를 통해 학습할 수 있다.
- 이는 데이터 수집이 어렵고 위험한 실제 환경에서 유용하며, 인간 전문가나 기존 데이터를 안전하게 활용할 수 있다.
- 미리 기록된 데이터를 활용함으로써, 훈련되지 않은 RL 에이전트의 탐색으로 인한 위험을 회피할 수 있다.
- Offline RL의 주요 과제: 외삽 오류(Extrapolation Error)
- Offline RL에서 중요한 문제는 데이터셋에 포함되지 않은 상태-동작 쌍에 대한 가치(Q-값)를 잘못 평가하는 외삽 오류이다.
- 기존의 off-policy RL 알고리즘은 offline 설정에서 적용 가능하지만, 외삽 오류로 인해 성능이 크게 저하된다.
- 이는 정책 평가에서 잘못된 가치 추정이 발생하여 잘못된 동작을 학습하게 만들고, 에이전트가 OOD 동작(Out-of-Distribution)을 과대평가하게 되어 정책 개선에 문제가 발생한다.
- Fujimoto et al., 2019b는 이러한 문제를 지적하며, 학습된 정책이 데이터 생성 과정(행동 정책)과 가깝게 유지되어야 한다고 주장한다.
- Offline RL에서 정책 제약 기법들
- 외삽 오류를 해결하기 위한 방법으로 학습된 정책이 데이터 생성 과정에 가깝게 유지되도록 하는 여러 접근들이 제안되었다.
- 이러한 접근 방식은 각각 batch-constrained [Fujimoto et al., 2019b], KL-control [Jaques et al., 2019], behavior-regularized [Wu et al., 2019], policy constraint [Levine et al., 2020] 등의 이름으로 불린다.
- 이러한 방법들의 공통적인 아이디어는, 학습된 정책이 행동 정책(behavior policy)에 너무 멀어지지 않도록 정규화나 제약을 가하는 것이다.
- 기존 알고리즘의 복잡성 문제
- 많은 offline RL 알고리즘은 성능을 높이기 위해 다양한 보조 구성 요소를 도입한다.
- 예를 들어, 생성 모델을 추가하거나 새로운 하이퍼파라미터를 도입하여 정책을 조정하는 등 기존의 온라인 RL 알고리즘을 상당히 수정하게 된다.
- 이러한 추가적인 구성 요소들은 재현 가능성을 떨어뜨리고, 튜닝 과정이 복잡해질 뿐만 아니라, 실행 시간도 크게 늘어난다.
- 또한, 성능 향상의 원인을 명확히 분석하거나 다른 알고리즘에 기법을 적용하는 데 어려움이 발생한다.
- 단순한 해결책을 탐구해야 할 필요성
- 이러한 복잡한 알고리즘적 접근은 offline RL에서의 실제적인 문제 해결을 어렵게 만들 수 있다.
- 기존의 복잡한 방법론을 단순화하여, 최소한의 변경만으로 offline RL이 가능하다면, 이는 큰 실용적 가치를 가진다.
- TD3 알고리즘을 활용한 최소주의적 접근 π=argmaxπE(s,a)∼D[λQ(s,π(s))−(π(s)−a)2]
- 본 논문에서는 기존 TD3 알고리즘 [Fujimoto et al., 2018]의 정책 업데이트 단계에 단순히 행동 복제(behavior cloning) 항을 추가함으로써 성능을 크게 향상시킬 수 있음을 제시한다.
- 구체적으로, TD3의 정책 업데이트는 기존의 결정론적 정책 기울기(deterministic policy gradient) [Silver et al., 2014]을 따르지만, 여기에 정규화 항을 추가한다:
- 여기서 λ는 정규화의 강도를 제어하는 단일 하이퍼파라미터로, 복잡한 조정 없이도 성능을 크게 향상시킬 수 있다.
- 데이터 정규화의 중요성
- 또한, 데이터셋에서 상태를 정규화하여 평균을 0, 표준편차를 1로 조정하는 것이 학습된 정책의 안정성을 높인다는 것을 발견했다.
- 이 정규화 과정은 정책의 안정적인 학습을 돕는 간단하지만 중요한 과정이다.
- 간단한 변화로 성능 향상
- 본 연구에서 제안한 TD3+BC는 단순한 코드 수정만으로 구현이 가능하며, 기존 offline RL 알고리즘들과 비슷한 수준의 성능을 달성한다.
- D4RL 벤치마크의 연속 제어 작업에서 실험한 결과, 제안된 알고리즘은 기존의 복잡한 방법들에 비해 더 적은 계산 비용으로 비슷한 성능을 달성하였다.
- 특히, 실행 시간이 절반 이상 감소하면서도 성능은 그대로 유지되는 점에서 단순한 방법이 복잡한 접근법에 비해 덜 탐구되었음을 보여준다.
(2022) [MCQ] Mildly conservative q-learning for offline reinforcement learning
https://arxiv.org/abs/2206.04745
Jiafei Lyu, Xiaoteng Ma, Xiu Li, Zongqing Lu
Abstract
- Offline RL은 고정된 데이터셋에서 학습하며, OOD 동작이 과대평가되지 않도록 가치 함수는 보수적이어야 함.
- 기존 방식들은 보수성을 유지하려다 일반화를 억제하며 성능을 제한함.
- MCQ(Mildly Conservative Q-learning)는 OOD 동작을 적절한 의사 Q 값을 통해 적극적으로 학습시킴.
- 이론적으로 MCQ는 행동 정책보다 성능이 나쁘지 않으며, OOD 동작에 대한 과대평가 오류가 발생하지 않도록 보장됨.
- D4RL 벤치마크 실험에서 MCQ는 탁월한 성능을 보였으며, 특히 offline에서 online으로 전환할 때 뛰어난 일반화 능력을 입증함.
Introduction
- 온라인 RL의 한계
- 온라인 RL은 에이전트가 환경과 지속적으로 상호작용하면서 학습해야 하는데, 이는 실세계 응용에서 비현실적이거나 불가능할 수 있음.
- 데이터 수집 과정은 종종 비용이 크고, 어려우며, 심지어 위험할 수 있음.
- 예: 자율주행, 로봇 제어, 헬스케어와 같은 실제 환경에서의 상호작용은 높은 위험을 초래할 수 있음.
- Offline RL의 등장
- Offline RL은 고정된 정적 데이터셋을 사용하여 학습을 진행하고, 환경과의 상호작용 없이 문제를 해결함으로써 위의 문제를 해결하고자 함 [36].
- 미리 수집된 데이터셋을 사용하기 때문에 추가적인 상호작용이 없으며, 리스크를 크게 줄임.
- Offline RL의 주요 도전 과제: 분포 차이 문제
- Offline RL에서 가장 큰 도전은 학습된 정책과 행동 정책 간의 상태-동작 방문 빈도 분포의 차이임.
- 학습된 정책은 새로운 동작을 탐색할 수 있지만, 이러한 Out-of-Distribution (OOD) 동작에 대한 평가에서는 외삽 오류(extrapolation error)가 발생할 수 있음.
- 이러한 오류는 부트스트래핑을 통해 더욱 악화되어 심각한 Q-값 과대평가 오류로 이어질 수 있음 [14, 34].
- Offline RL에서 가장 큰 도전은 학습된 정책과 행동 정책 간의 상태-동작 방문 빈도 분포의 차이임.
- 기존 보수적 방법의 한계
- 기존의 Offline RL 방법들은 보수성을 유지하기 위해 몇 가지 전략을 사용함:
- 학습된 정책이 행동 정책에 가깝도록 정규화 [14, 58, 34, 13, 57].
- OOD 동작의 Q-값을 과도하게 비관적으로 패널티화 [35, 33, 59].
- OOD 샘플을 아예 사용하지 않고 학습 [56, 8, 62, 32, 40].
- 하지만 이러한 방식들은 과도한 보수성으로 인해 일반화 능력을 제한하고, 성능이 저하되는 문제가 발생함.
- 특히, 낙관적 가치 추정이 필요한 상황에서도 정책이 과도하게 비관적으로 학습됨.
- 기존의 Offline RL 방법들은 보수성을 유지하기 위해 몇 가지 전략을 사용함:
- 일반화와 성능 향상을 위한 필요성
- 신경망은 연속적인 state-action 공간에서 학습된 데이터를 인접한 보지 못한 상태와 동작으로 일반화해야 함.
- 예를 들어, 비최적 경로를 결합해 최적 경로를 생성할 수 있도록 하는 능력이 중요함.
- 그러나 기존의 보수성 유지 기법은 이러한 일반화를 저해하고, 에이전트의 성능 향상을 막음.
- 정책 정규화는 수집된 데이터의 질이 낮을 경우 신뢰도가 떨어지며, 가치 패널티 방식은 데이터셋 내와 OOD 영역 모두에서 불필요하게 비관적이 됨.
- 신경망은 연속적인 state-action 공간에서 학습된 데이터를 인접한 보지 못한 상태와 동작으로 일반화해야 함.
- Mildly Conservative Q-learning (MCQ)의 제안
- 우리는 필요 최소한의 보수성을 유지하는 새로운 방식인 **Mildly Conservative Q-learning (MCQ)**을 제안함.
- MCQ는 OOD 동작을 적절한 의사 Q 값을 할당해 적극적으로 학습하며, 일반화를 해치지 않으면서 보수성을 유지함.
- OOD 동작의 Q 값을 약간 낙관적으로 설정하여 성능 향상과 보수성 간의 균형을 맞춤.
- 이로 인해 Q(s, a^ood) < max_{a∈Support(µ)} Q(s, a) 조건을 충족시키면서 OOD 동작에 대한 잘못된 과대평가가 발생하지 않도록 보장함.
- 우리는 필요 최소한의 보수성을 유지하는 새로운 방식인 **Mildly Conservative Q-learning (MCQ)**을 제안함.
- Mildly Conservative Bellman (MCB) 연산자
- MCB 연산자는 OOD 동작에 대해 더 나은 가치 추정을 제공하고, 이를 적극적으로 학습하며, 성능을 개선하는 새로운 기법임.
- 이론적으로 MCB 연산자는 학습된 정책이 행동 정책보다 성능이 나쁘지 않도록 하며, 기존 보수성 기법보다 더 엄격한 하한을 보장함.
엄격한 하한을 둔다 = 정책의 성능 평가에서, 학습된 Q-값이 지나치게 낙관적이지 않도록 보수적인 값을 유지하는 것을 의미
- 정책이 데이터셋에 존재하는 동작에 대해 학습된 Q-값을 사용할 때는 일반적인 Bellman 백업을 수행하지만, OOD 동작에 대해서는 신뢰할 수 없는 값을 가지지 않도록 고의적으로 낮은 Q-값을 할당한다.
- 이를 통해 OOD 동작에 대해 낙관적일 수 없는 Q-값을 보장하면서, OOD 동작이 학습된 정책에서 선택되지 않도록 한다.
MCB 연산자의 OOD 동작에 대한 가치 추정 메커니즘
- OOD 동작을 적극적으로 학습: MCB 연산자는 OOD 동작을 단순히 무시하지 않고, 해당 동작들에 적절한 Q-값을 할당한다. 이를 통해 OOD 동작을 학습 과정에서 고려하게 된다.
- 구체적으로, OOD 동작에 대해서는 maxa'∼Support(µ(·|s))Q(s, a')와 같은 상한을 두고, 이를 초과하지 않도록 한다. 이 방식은 학습된 정책이 최적 행동 정책을 추정하면서도 과대평가하지 않도록 보장한다.
- T1과 T2의 이중 백업: MCB 연산자는 OOD 동작을 확인하고, T1과 T2 연산을 통해 OOD 동작에 대해 낮은 Q-값을 할당한다.
- T1은 정책이 행동 정책(behavior policy)에서 지원(support)되는 영역 안에 있는지 확인하는 역할을 한다.
- 지원 내 동작: 정책 동작이 행동 정책 지원 내에 있다면 Q(s, a) 반환
- 지원 외 동작: OOD 동작으로 간주하고, 해당 동작에 대해 가상의 pseudo target value을 할당
- T2는 이를 기반으로 OOD 동작의 Q-값을 평가하는 단계이다. 이 과정은 OOD 동작이 학습에 포함되면서도 과대평가되지 않도록 보장한다.
- 지원 내 동작: 표준 Bellman 연산을 사용해서 Q값을 업데이트
- 지원 외 동작: OOD 동작에 대해서는 r(s, a) + γEs′ [Q(s, a)] 값을 사용하여 보수적인 값을 할당
- T1은 정책이 행동 정책(behavior policy)에서 지원(support)되는 영역 안에 있는지 확인하는 역할을 한다.
- δ 값을 통한 보수성 조정: OOD 동작에 대해 설정된 Q-값에서 δ(델타) 값을 빼서 이 Q-값을 약간 낮게 설정한다. 이로 인해 OOD 동작이 정책에서 선택되지 않도록 조정하며, 잘못된 과대평가를 방지한다.
- MCQ의 적용 및 성능
- 조건부 변동 자동 인코더(CVAE)로 행동 정책을 추정하고, Soft Actor-Critic (SAC) 알고리즘과 결합한 MCQ는 D4RL MuJoCo 이동 작업에서 기존 방법들을 대부분 능가하는 성능을 보였음.
- 특히, 비전문가(non-expert) 데이터셋에서 뛰어난 성능을 발휘.
- 또한, offline에서 online으로 전환할 때도 우수한 일반화 능력을 보여, 온건한 비관주의가 offline 학습에 중요함을 입증.
- 조건부 변동 자동 인코더(CVAE)로 행동 정책을 추정하고, Soft Actor-Critic (SAC) 알고리즘과 결합한 MCQ는 D4RL MuJoCo 이동 작업에서 기존 방법들을 대부분 능가하는 성능을 보였음.
(2023) [PRDC] Policy Regularization with Dataset Constraint for Offline Reinforcement Learning
https://arxiv.org/abs/2306.06569
Yuhang Ran, Yi-Chen Li, Fuxiang Zhang, Zongzhang Zhang, Yang Yu
Abstract
- Offline RL은 고정된 데이터셋에서 학습하는데, 기존 방법들은 학습된 정책을 행동 정책의 분포나 지원으로 제약함.
- 이러한 제약은 지나치게 보수적이어서, 특히 행동 정책이 비최적일 때 학습된 정책의 성능을 제한할 수 있음.
- PRDC(Policy Regularization with Dataset Constraint)는 상태-동작 쌍에서 가장 가까운 이웃을 찾아, 정책을 더 나은 동작으로 가이드함.
- PRDC는 부드러운 제약을 제공하면서도 OOD 동작으로부터 충분한 보수성을 유지함.
- PRDC는 가치 과대평가 문제를 완화하고, 기존 방법들과 비교하여 최첨단 성능을 달성함.
Introduction
- 온라인 RL의 성공과 한계
- 온라인 RL은 게임(Silver et al., 2017), 로봇공학(Li et al., 2021), 추천 시스템(Chen et al., 2018) 등에서 주목할 만한 성공을 이루었다.
- 하지만, 온라인 RL은 지속적인 환경과의 상호작용을 요구하며, 이는 비용이 크거나, 안전 문제가 있어 실제 응용에서는 어려움을 야기할 수 있다.
- 온라인에서 최적의 정책을 학습하려면 에이전트가 시행착오 방식으로 환경과 수백만 번 이상 상호작용해야 한다(Sutton & Barto, 2018).
- 이는 데이터 수집 비용이 매우 크거나 위험한 상황에서는 실현하기 어려워, 실제 응용에서 제한된다.
- Offline RL의 장점과 최근 관심
- Offline RL은 미리 수집된 고정된 데이터셋을 기반으로 학습하며, 훈련 중 추가 상호작용이 필요 없다.
- 이를 통해 안전하지 않은 환경이나, 데이터 수집 비용이 큰 응용에서 RL을 적용할 수 있는 가능성을 제공한다.
- Offline RL은 특히 기존 데이터셋을 강력한 의사결정 엔진으로 전환할 수 있다는 잠재력 덕분에 최근 몇 년간 많은 관심을 받아왔다(Levine et al., 2020).
- 이는 RL의 데이터 기반 접근을 확장하는 중요한 방향성을 제시한다.
- Offline RL의 주요 문제: OOD 동작에 대한 가치 과대평가
- Offline RL에서의 근본적인 문제는, Out-of-Distribution (OOD) 동작에 대해 가치(Q-값)가 과대평가되는 경향이 있다는 것이다(2.3절 참조).
- OOD 동작은 행동 정책에 의해 자주 수행되지 않은 동작으로, 이런 동작에 대한 신뢰할 수 있는 평가 데이터를 충분히 확보하기 어렵다.
- 에이전트는 OOD 동작에 대해 잘못된 가치 추정을 할 수 있으며, 이는 정책 개선에 부정적인 영향을 미친다. 에이전트가 잘못된 동작을 선호하게 되어 성능이 크게 저하된다.
- OOD 동작을 다루는 기존의 두 가지 주요 접근 방식
- 비관적 가치 기반 접근법
- OOD 동작의 가치를 과소평가하거나, 보수적인 가치 함수를 학습하여 에이전트가 OOD 동작을 선택하지 않도록 유도한다(Kumar et al., 2020; Yu et al., 2021).
- 이 접근법은 에이전트가 낙관적인 동작 선택을 억제하고, 학습된 정책이 OOD 동작을 피할 수 있도록 한다.
- 정규화된 정책 기반 접근법
- 정책을 데이터셋에서 자주 나타나지 않는 상태-동작을 피하도록 정규화하거나 제약을 가한다(Fujimoto et al., 2019; Nair et al., 2020).
- 이 접근은 주어진 데이터셋에 충분히 포함된 동작만을 선택하도록 정책을 제약하며, OOD 동작을 탐색하지 않게 한다.
- 비관적 가치 기반 접근법
- 정책 정규화의 한계
- 기존의 정책 정규화 접근법은 학습된 정책을 행동 정책의 분포(Wu et al., 2019) 또는 행동 정책의 지원(Kumar et al., 2019)으로 제약한다.
- 이러한 방법은 특정 상태에서 정책이 행동 정책의 동작만을 선택하도록 강요하여, 지나치게 보수적일 수 있다.
- 특히, 행동 정책이 비최적일 때, 정책이 비효율적인 행동을 선택하게 되어 성능이 제한된다.
- 또한, 주어진 상태에서 최적의 동작이 없을 때도, 제한된 동작 선택지만으로 학습된 정책을 제약하는 것은 성능을 저하시킬 수 있다.
- 새로운 정책 정규화 접근의 필요성
- 특정 상태에서 최적의 동작이 주어진 데이터셋 내에 없을 경우, 에이전트가 더 나은 동작을 선택할 수 있는 유연성이 필요하다.
- 주어진 상태에 국한된 동작이 아닌, 데이터셋 전체에서 더 나은 동작을 선택하도록 정책을 가이드할 수 있는 방법을 제시할 필요가 있다.
- 이러한 필요성은 더 부드러운 정책 정규화 기법의 개발로 이어진다.
- PRDC(Policy Regularization with Dataset Constraint)의 제안
- 본 연구에서는 주어진 상태에서 학습된 정책이 가장 가까운 상태-동작 이웃(nearest neighbor)을 기반으로 동작을 선택하는 새로운 방법인 PRDC를 제안한다.
- PRDC는 주어진 상태에서 데이터를 탐색하여, 해당 상태와 가장 가까운 상태-동작 쌍을 찾아 이를 정책의 제약으로 사용한다.
- 이는 기존의 분포 또는 지원 기반 제약과 달리, 데이터셋 전체를 활용하여 더 나은 동작을 선택할 수 있도록 가이드하는 방법이다.
- PRDC는 주어진 상태에서 존재하지 않는 더 나은 동작을 허용하면서도, 충분한 보수성을 유지하여 OOD 동작의 잘못된 선택을 방지한다.
- PRDC의 성능 및 구현
- PRDC는 TD3(Fujimoto et al., 2018)와 같은 Actor-Critic 알고리즘에 결합할 수 있으며, 이를 기반으로 고효율적 구현을 제공한다(3절 참조).
- 실험 결과, PRDC는 기존의 방법들보다 가치 과대평가 문제를 효과적으로 완화하면서도, 성능 격차를 최소화할 수 있음을 입증했다.
- 특히, Gym 및 AntMaze 작업에서 PRDC는 기존 알고리즘들과 비교하여 최첨단 성능을 달성했다(5절 참조).
'ML & DL > RL' 카테고리의 다른 글
| [RL] offline RL constraint 유형 정리 (0) | 2024.09.24 |
|---|---|
| [RL paper] Deep reinforcement learning in transportation research: A review (1) | 2024.09.05 |
| [RL] Offline Reinforcement Learning: From Algorithms to Practical Challenges 강의 해석 (2) (0) | 2024.08.12 |
| [RL] Offline Reinforcement Learning: From Algorithms to Practical Challenges 강의 해석 (1) (0) | 2024.08.11 |
| [RL] Actor-Critic 알고리즘 간단하게 개념 정리 (0) | 2024.08.05 |