
혁펜하임님의 "혁펜하임의 “트이는” 강화 학습" 을 바탕으로 정리한 글입니다.
policy-based 이전에는 value-based 개념이 있었는데, value-based에서는 state value function을 최대화하는 policy를 찾자는 내용이었다.
이를 위해서는 greedy action하는 것이 좋은 정책을 찾는데 좋은 방법이었지만, 또 너무 greedy한 action을 찾다보면 sub optimal에 빠지기 쉽게 때문에 exploration을 적절하게 실행하는 ε-greedy 방법을 주로 사용하였다. (예: DQN)
하지만, value-based 방법에는 몇 가지 한계가 존재한다.
- 연속적인 공간에서의 어려움 value-based 방법은 상태 공간이 이산적일 때 효과적이다. 하지만 상태 공간이 연속적일 경우, 모든 상태를 저장하고 업데이트하는 것이 매우 비효율적이다. 고차원 연속 공간에서는 상태의 수가 무한하기 때문에, 이를 처리하는 데 어려움이 많다. 이로 인해 연속적인 상태 공간을 다루는 데 적합하지 않다.
- 확률적 정책(Stochastic Policy)의 경우 value-based 방법은 주로 결정론적 정책을 사용하여 최적의 행동을 선택한다. 하지만 실제 환경에서는 확률적 정책이 더 유리한 경우가 많다.
예를 들어, 아래 이미지에서 볼 수 있듯이, 특정 상태에서 다양한 방향으로 이동할 수 있는 확률적 정책이 필요할 수 있다. 이미지에서 돈 주머니를 목표로 하는 경우, 회색 박스에서는 왼쪽이나 오른쪽 방향으로만 가는 determinstic한 optimal한 policy에 도달할 수 없다. 이 상태에서는 확률적으로 행동을 선택하는 것이 더 바람직할 수 있다. value-based 접근 방식은 이러한 확률적 행동을 효과적으로 다루기 어렵다.
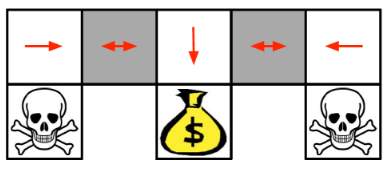
따라서, policy-based 라는 개념이 등장하였고, 기존에는 value값을 최대화 하는 action을 선택하는 개념이었다면 이제는 action 선택을 policy에 따라 하는 거니까 policy 그 자체를 찾아내자는 의미가 된다. 즉, state가 주어졌을 때 어떤 action을 고를지에 대한 분포를 잘 찾자는 내용이 된다.
예를 들어, 그 분포가 가우시안 분포라고 하면 네트워크를 통해서 input으로 state가 들어가고 output으로 뮤와 시그마를 찾는 것이다.
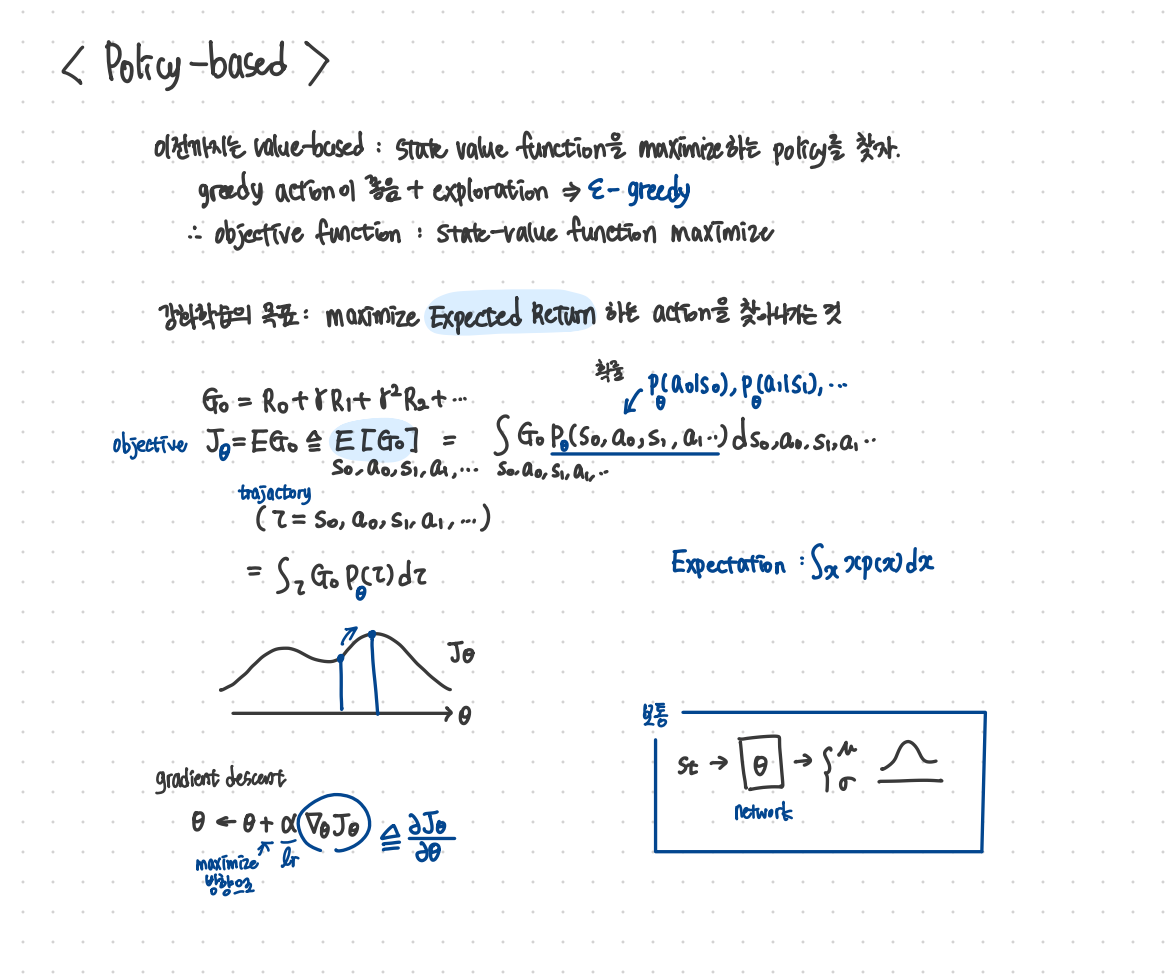
강화학습의 목표는 이전과 같이 expected return을 최대화하는 action을 찾아나가는 것이기 때문에 objective 식은 아래와 같이 작성할 수 있다.
$J_{\theta} = \mathbb{E}_{\theta}[G_{\tau}] \triangleq \mathbb{E}[G_{\tau}] = \int_{\tau} G_{\tau} P_{\theta}(s_{0}, a_{0}, s_{1}, a_{1}, \dots) ds_{0} da_{0} ds_{1} da_{1} \dots$
아래 식은 $\theta$ 로 parameterized 된 식을 표현한 것이고 이를 gradient descent를 통해서 maximize하려면 $\theta$ 는 다음과 같이 업데이트가 진행되어야 한다.
$\theta \leftarrow \theta + \alpha \nabla_{\theta} J_{\theta}$
'ML & DL > RL' 카테고리의 다른 글
| [RL] 강화학습 REINFORCE 알고리즘 (0) | 2024.07.31 |
|---|---|
| [RL] 강화학습 Policy Gradient 수식 전개 (0) | 2024.07.31 |
| [RL paper] Double DQN: Deep Reinforcement Learning with Double Q-learning 리뷰 (0) | 2024.07.11 |
| [RL] 간단하게 정리한 On-policy, Off-policy, Online, Offline Reinforcement Learning (0) | 2024.06.13 |
| [RL] 강화학습이란 (0) | 2023.09.06 |
혁펜하임님의 "혁펜하임의 “트이는” 강화 학습" 을 바탕으로 정리한 글입니다.
policy-based 이전에는 value-based 개념이 있었는데, value-based에서는 state value function을 최대화하는 policy를 찾자는 내용이었다.
이를 위해서는 greedy action하는 것이 좋은 정책을 찾는데 좋은 방법이었지만, 또 너무 greedy한 action을 찾다보면 sub optimal에 빠지기 쉽게 때문에 exploration을 적절하게 실행하는 ε-greedy 방법을 주로 사용하였다. (예: DQN)
하지만, value-based 방법에는 몇 가지 한계가 존재한다.
- 연속적인 공간에서의 어려움 value-based 방법은 상태 공간이 이산적일 때 효과적이다. 하지만 상태 공간이 연속적일 경우, 모든 상태를 저장하고 업데이트하는 것이 매우 비효율적이다. 고차원 연속 공간에서는 상태의 수가 무한하기 때문에, 이를 처리하는 데 어려움이 많다. 이로 인해 연속적인 상태 공간을 다루는 데 적합하지 않다.
- 확률적 정책(Stochastic Policy)의 경우 value-based 방법은 주로 결정론적 정책을 사용하여 최적의 행동을 선택한다. 하지만 실제 환경에서는 확률적 정책이 더 유리한 경우가 많다.
예를 들어, 아래 이미지에서 볼 수 있듯이, 특정 상태에서 다양한 방향으로 이동할 수 있는 확률적 정책이 필요할 수 있다. 이미지에서 돈 주머니를 목표로 하는 경우, 회색 박스에서는 왼쪽이나 오른쪽 방향으로만 가는 determinstic한 optimal한 policy에 도달할 수 없다. 이 상태에서는 확률적으로 행동을 선택하는 것이 더 바람직할 수 있다. value-based 접근 방식은 이러한 확률적 행동을 효과적으로 다루기 어렵다.
따라서, policy-based 라는 개념이 등장하였고, 기존에는 value값을 최대화 하는 action을 선택하는 개념이었다면 이제는 action 선택을 policy에 따라 하는 거니까 policy 그 자체를 찾아내자는 의미가 된다. 즉, state가 주어졌을 때 어떤 action을 고를지에 대한 분포를 잘 찾자는 내용이 된다.
예를 들어, 그 분포가 가우시안 분포라고 하면 네트워크를 통해서 input으로 state가 들어가고 output으로 뮤와 시그마를 찾는 것이다.
강화학습의 목표는 이전과 같이 expected return을 최대화하는 action을 찾아나가는 것이기 때문에 objective 식은 아래와 같이 작성할 수 있다.
$J_{\theta} = \mathbb{E}_{\theta}[G_{\tau}] \triangleq \mathbb{E}[G_{\tau}] = \int_{\tau} G_{\tau} P_{\theta}(s_{0}, a_{0}, s_{1}, a_{1}, \dots) ds_{0} da_{0} ds_{1} da_{1} \dots$
아래 식은 $\theta$ 로 parameterized 된 식을 표현한 것이고 이를 gradient descent를 통해서 maximize하려면 $\theta$ 는 다음과 같이 업데이트가 진행되어야 한다.
$\theta \leftarrow \theta + \alpha \nabla_{\theta} J_{\theta}$
'ML & DL > RL' 카테고리의 다른 글
| [RL] 강화학습 REINFORCE 알고리즘 (0) | 2024.07.31 |
|---|---|
| [RL] 강화학습 Policy Gradient 수식 전개 (0) | 2024.07.31 |
| [RL paper] Double DQN: Deep Reinforcement Learning with Double Q-learning 리뷰 (0) | 2024.07.11 |
| [RL] 간단하게 정리한 On-policy, Off-policy, Online, Offline Reinforcement Learning (0) | 2024.06.13 |
| [RL] 강화학습이란 (0) | 2023.09.06 |