
728x90
반응형
혁펜하임님의 "혁펜하임의 “트이는” 강화 학습" 을 바탕으로 기록한 내용입니다.
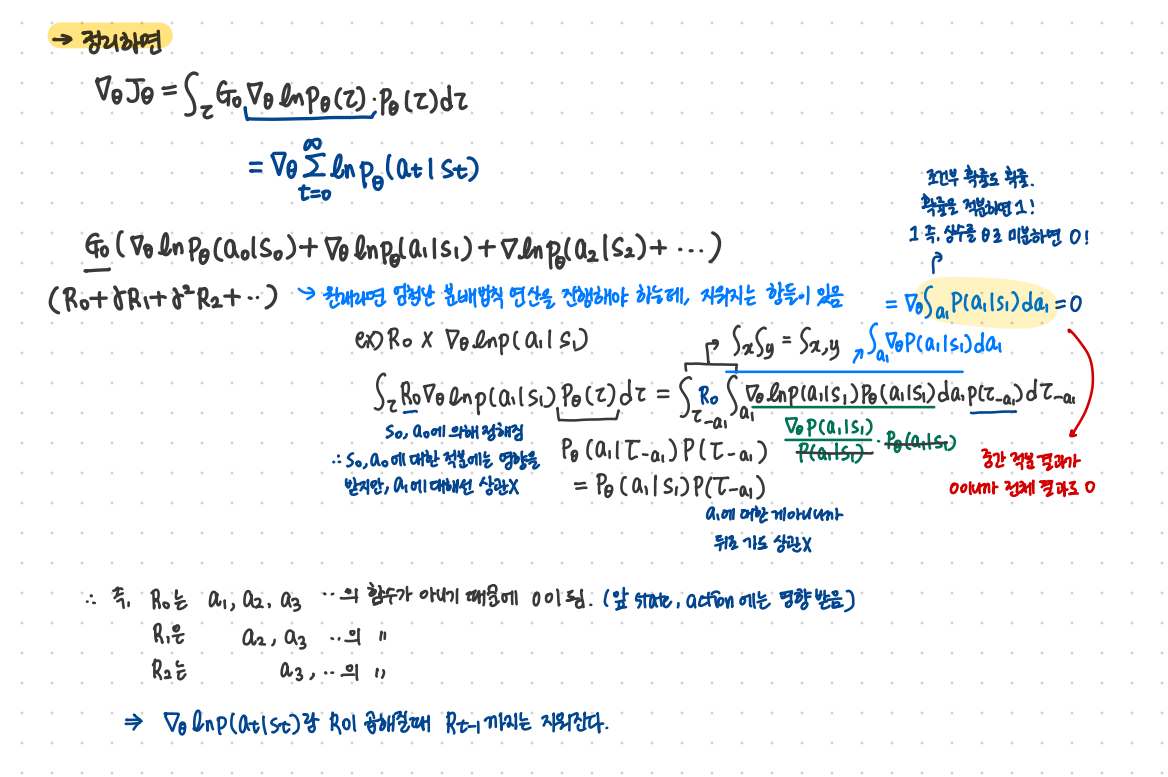
아래 내용은 강의를 보고 policy gradient 내용을 수식으로 쭉 정리한 내용이다.


728x90
반응형
LIST
'ML & DL > RL' 카테고리의 다른 글
| [RL] Actor-Critic 알고리즘 간단하게 개념 정리 (0) | 2024.08.05 |
|---|---|
| [RL] 강화학습 REINFORCE 알고리즘 (0) | 2024.07.31 |
| [RL] 강화학습 Policy-based 개념 간단 정리 (0) | 2024.07.31 |
| [RL paper] Double DQN: Deep Reinforcement Learning with Double Q-learning 리뷰 (0) | 2024.07.11 |
| [RL] 간단하게 정리한 On-policy, Off-policy, Online, Offline Reinforcement Learning (0) | 2024.06.13 |
728x90
반응형
혁펜하임님의 "혁펜하임의 “트이는” 강화 학습" 을 바탕으로 기록한 내용입니다.
아래 내용은 강의를 보고 policy gradient 내용을 수식으로 쭉 정리한 내용이다.
728x90
반응형
LIST
'ML & DL > RL' 카테고리의 다른 글
| [RL] Actor-Critic 알고리즘 간단하게 개념 정리 (0) | 2024.08.05 |
|---|---|
| [RL] 강화학습 REINFORCE 알고리즘 (0) | 2024.07.31 |
| [RL] 강화학습 Policy-based 개념 간단 정리 (0) | 2024.07.31 |
| [RL paper] Double DQN: Deep Reinforcement Learning with Double Q-learning 리뷰 (0) | 2024.07.11 |
| [RL] 간단하게 정리한 On-policy, Off-policy, Online, Offline Reinforcement Learning (0) | 2024.06.13 |